
|
accueil > Contenu > Yang > Anneau > Analyse de Données |
 Numéro d'enregistrement : 00041985 |
Ce site est protégé par droit d'auteur. En l'occurrence, ce certificat de droit d'auteur n'est pas une licence d'exploitation : Ce qui est protégé est l'archivage officiel du contenu des pages à une date précise. Ainsi l'antériorité d'une création pourra être prouvée, c'est-à-dire que toute idée nouvelle circulant sur Internet et qui serait ma création pourrait être reconnue comme telle grâce à ce dépôt légal... |
Sommaire
Statistique et analyse de données
Tous les travaux, exemples et théories de cette page peuvent être vérifiés en utilisant le logiciel gratuit RapidMiner/Yale.Toutes les techniques que j'expose dans cette page, ainsi que dans celle du "data mining", sont très matheuses. Ce sont pourtant ces méthodes qui font la fortune des grandes entreprises, et ce sont également les seules méthodes qui permettent d'éclaircir la complexité d'un monde globalisant. Ce n'est pas un hasard si j'ai ressenti le besoin de les exposer...
L'analyse de données, vocable ambigü, est pourtant une théorie novatrice mise au point dans les années 1960 en France par le professeur J.P. Benzecri à Lyon. Elle s'appuie sur la statistique traditionnelle, et a pour ambition de la prolonger afin d'explorer des données et de leur découvrir des structures cachées, inconnues, utiles et explicables.
Le professeur Benzecri insistait sur la nécessité de ne pas avoir d'a priori sur les structures et les données à explorer. Cette disposition intellectuelle conditionne la compréhension et l'utilité des méthodes proposées, et peut provoquer de vifs débats sur le caractère scientifique d'une telle théorie.
En fait, tout débat sur l'analyse de données et sur son jumeau américain du MIT, le Data Mining doit être compris comme un débat strictement stérile sur le plan technique, mais d'un certain intérêt sociologique. En outre, l'analyse de données n'utilise pas exactement les mêmes modèles ni les mêmes soubassements théoriques que la statistique : en fait, elle inclue des théories extrinsèques qui peuvent semer la confusion quant à sa nature; le professeur Benzecri avait donc développé un appareil de justification théorique particulièrement impressionnant, qui peut conduire à croire que l'analyse de données devrait s'appréhender de manière rigoureuse et intellectuelle.
Une anecdote amusante sur le professeur Benzecri : Un jour qu'il devait livrer une conférence sur l'analyse de données dans un amphithéâtre, le professeur arriva largement en avance sur les lieux. Le gardien responsable des infrastructures faisait sa ronde, et constata avec surprise qu'un homme mal vêtu, avec une barbe de patriarche biblique, "squattait" les lieux. Il chassa le supposé clochard qui n'était autre que le professeur Benzecri. Il paraît que le gardien a eu des soucis par la suite...
L'analyse de données est donc un hybride théorique, qui ne se justifie que par sa vocation :
Aider tout analyste, quel qu'il soit, à explorer ses propres données et à les faire parler.Du point de vue du statisticien, l'exploration des données se résume à :
- Présenter un panorama des données, c'est la statistique descriptive
- Mesurer la représentativité d'un échantillon par rapport à une population théorique : c'est la statistique inférentielle
- Comparer deux échantillons entre eux, avec ou sans référence à une population d'origine : c'est le test d'hypothèses, sorte de prolongement de la statistique inférentielle.
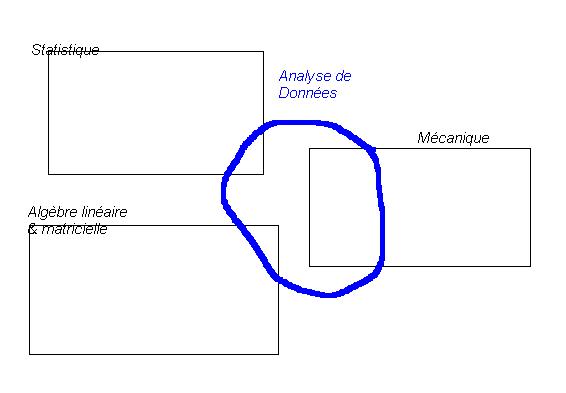
Je présente ci-dessous un petit schéma de repérage de l'analyse de données par rapport à d'autres disciplines dont la statistique. Vous trouverez également une carte complète de concepts présentant tous les tenants et aboutissants de ce genre de discipline : l'analyse de données et le data mining
Les modèles
L'analyse de données utilise trois modèles pour présenter et pour expliquer les données. Il s'agit de raisonner par analogie : Si l'on considère les données comme des objets réels, munis d'un poids, alors on pourra utiliser les théorèmes de la mécanique traditionnelle, reliant force, accélération, position, énergie et masse, pour peu que l'on ait été capable d'identifier ce qui joue le rôle de masse, d'accélération, etc.... L'utilisation de tels modèles est donc soumise à interprétation, qui a pour but de distribuer les rôles aux écritures utilisées. Si l'identification des rôles fonctionne bien, cela laisse présager que le modèle est applicable, et alors l'utilisation des théorèmes du domaine analogue permet de déduire de nouvelles formules d'exploitation des données.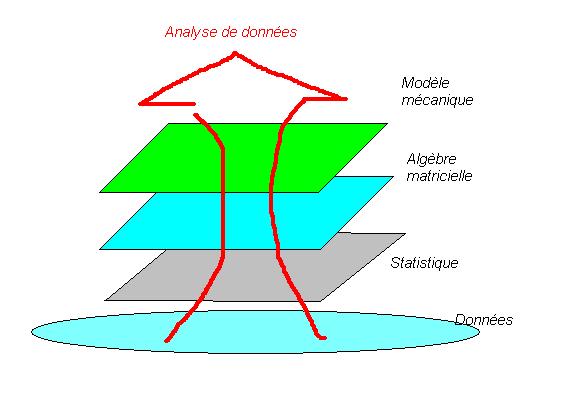
modèle algébrique
notions sur les matrices
Le principe du modèle algébrique est d'utiliser l'algèbre matricielle et de l'appliquer aux données statistiques. Je rappelle, sans déflorer le sujet, que l'algèbre matricielle consiste à traiter des matrices, des tableaux de nombres qui représentent la dépendance des données entre elles. En l'occurrence, cette dépendance est de type linéaire, c'est-à-dire qu'une valeur "B" sera constituée des contributions des valeurs A, C et D selon les termes :B=axA+dxD+cxCLa première rangée de la matrice correspondante est alors constituée des nombres "a", "c" et "d". On a alors des matrices d'entrée, des matrices de passage, des matrices de résultat, des opérateurs pour modifier globalement les matrices. Un système d'équations à plusieurs inconnues se ramène à une équation matricielle de type [Y]=[A][X], et il suffit d'inverser la matrice [A], pour écrire [X]=[inv:A][Y] pour lire directement la solution.
On imagine la puissance d'un tel concept dans le traitement de données croisées, pour ainsi dire dans tous les domaines de la vie courante !![1]
Le modèle d'écriture de la table d'analyse
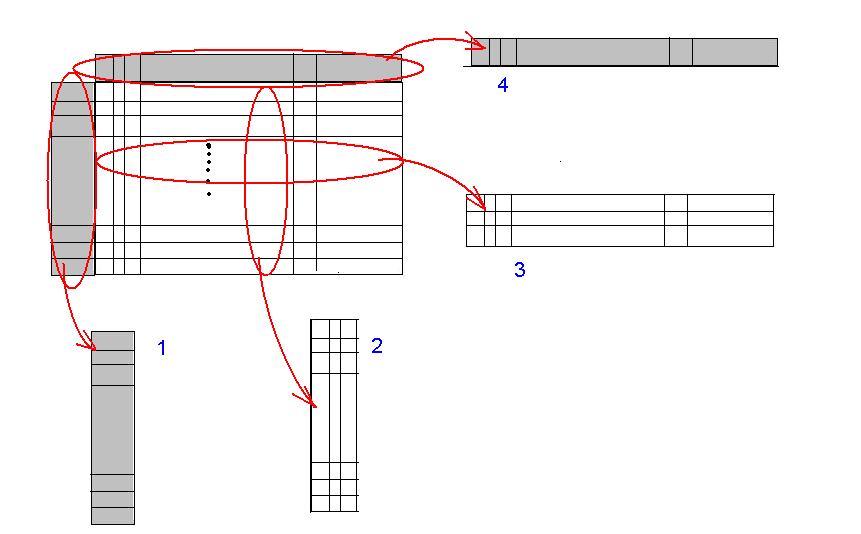
L'application du modèle matriciel à l'analyse de données suppose certaines conventions au regard du format des données :- La table d'analyse :
- Les données sont ramenées à des individus d'une population, chaque individu est caractérisé par les mêmes variables, mais qui prennent des valeurs différentes pour chaque individu. Ce sont en quelque sorte les "coordonnées" des individus. On obtient alors un tableau avec les individus en rangées, et les variables en colonnes.
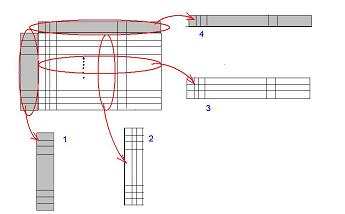
- Les quatre parties : valeurs (individus, attributs), intitulés (individus, attributs).
- L'idée est de séparer les libellés de la table de l'analyse, des valeurs que ces libellés peuvent prendre. Si une colonne porte un nom, alors on sépare la série de valeurs de cette colonne et le nom de la colonne, considérant alors qu'il y a un objet "colonne de valeurs" et un objet "intitulé de colonne". On fait de même avec les lignes, et on obtient quatre familles d'objets :
- les intitulés de lignes,
- les intitulés de colonnes,
- les lignes de valeurs
- et les colonnes de valeurs.
Le statut des intitulés est de dire : "Si j'applique un intitulé sur la table d'analyse, je ne dois obtenir que la ligne ou la colonne de valeurs correspondant originalement à l'intitulé". Chaque intitulé peut donc être interprété comme un masque, un filtre sur la table complète ne laissant "passer" que les valeurs relatives à l'intitulé. En outre :- Si j'applique sur ma table un masque, puis j'applique un autre masque sur le résultat (intitulé différent du premier), je dois obtenir...rien du tout !
- Si j'applique sur ma table une juxtaposition de deux masques, je dois obtenir une juxtaposition de deux colonnes/lignes de valeurs
- Si j'applique deux fois de suite le même masque sur la table puis sur le filtrat, j'obtiens le même résultat, à savoir le premier filtrat
- En fin de compte, la nature des masques ne s'identifie qu'à travers l'effet qu'ils produisent sur les valeurs
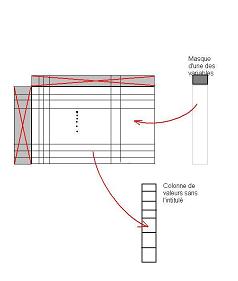
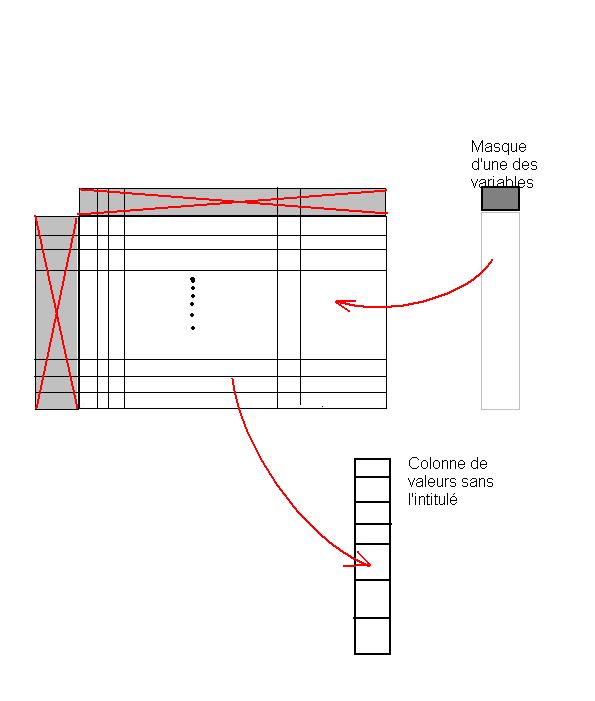
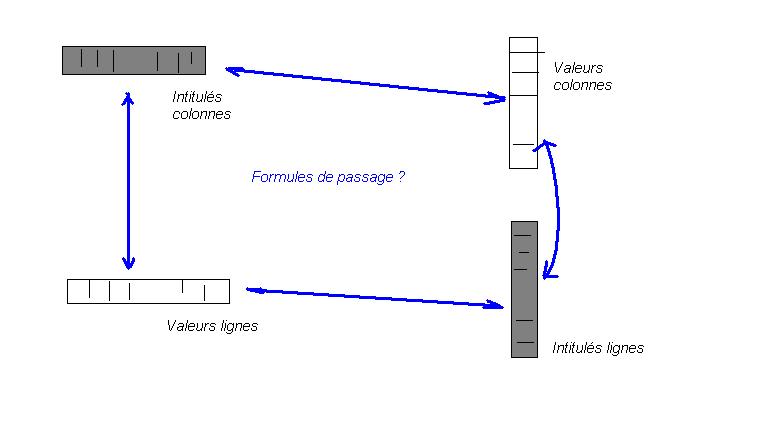
Le masque d'une colonne est associé
à l'intitulé de la colonne,
formant un objet-vecteurLa table d'analyse complète donne naissance à quatre
espaces vectoriels liés entre eux,
ce qui traduit l'unité initiale de la table - L'interprétation de ces quatre parties et leur interdépendance :
- L'idée initiale du professeur Benzécri était de pouvoir modifier de manière judicieuse la répartition des intitulés de colonnes. Revenant du Royaume-Uni, il avait vu les anglais pratiquer le "multidimensional scaling" et était convaincu de l'utilité de pouvoir modifier les intitulés plutôt que de les ordonnancer comme le firent les anglais.
Modifier les intitulés pouvait par exemple servir à mettre en lumière des variables moins nombreuses, mais représentatives de l'information contenue dans chacune des variables initiales. Ainsi, les dépenses mensuelles d'un ménage, le revenu mensuel, le taux d'endettement, le nombre d'enfants peuvent-il probablement expliquer conjointement le niveau d'épargne d'un ménage...On passe alors par exemple d'une centaine de variables en colonnes à quelques dizaines, ce qui accroit considérablement la lisibilité et permet d'expliquer des phénomènes et des thèmes.
Concrètement, sur la table d'analyse, cela suppose de savoir transformer :- Les intitulés de colonnes
- Les valeurs de colonne
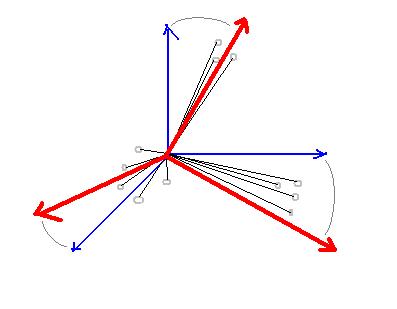
Pour déterminer la transformation la plus intelligente sur ces intitulés, l'idée du professeur Benzécri était de considérer une représentation visuelle et géométrique des différents individus : Chaque individu peut être considéré comme un point, dont les coordonnées sont les valeurs sur la rangée de l'individu. Changer les intitulés des colonnes revient à effectuer un changement de perspective graphique autour des individus, selon des modalités restant à définir et combinant des opérations de rotation, translation, zoom avant ou arrière exclusivement (pas de déformation ni effet miroir)..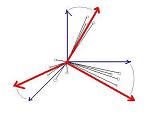
Les individus (ronds gris) sont des points avec coordonnées
( chaque axe bleu sur le dessin représente une colonne
de valeurs dans la table). On les considère comme
des vecteurs (traits noirs). Au vu de leur répartition
propre, il serait plus judicieux de les représenter selon
les axes rouges. Le problème est de trouver
ces axes rouges, et d'effectuer la "bascule bleu/rouge"
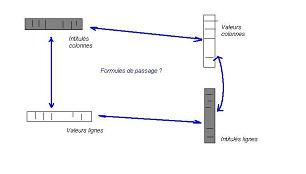
Récapitulons :- Les quatre espaces sont liés en théorie
- Il s'agit d'expliciter ces quatre liens en formules de passage
- On cherchera à utiliser ces quatre formules de manière à s'en servir de métrique
- Dotés d'une métrique, et ayant la garantie que la manipulation des espaces de valeurs conduit à la manipulation des intitulés, on peut essayer de trouver la meilleure opération géométrique (typiquement une rotation doublée de plusieurs zooms sélectifs) de manière à simplifier les intitulés
- La manipulation des intitulés :
- L'intérêt de manipuler les intitulés permet d'envisager de regrouper les individus entre eux, comme dans l'opération de "clustering", ou également de réduire les variables comme je l'ai expliqué plus haut. En fait, une réduction de variables consiste à compresser l'information contenue dans les variables, il y aura donc un compromis à faire entre le pouvoir de synthèse de la compression et sa fidélité aux données initiales. Pour ce faire, l'utilisation et l'interprétation de la métrique, doublée du modèle mécanique permet de mettre en évidence un indicateur simple et efficace de la représentativité de chaque variable nouvellement synthétisée. Il s'agit de la variance cumulée ou variance explicative. Ainsi une variable représentant 40% de la variance cumulée sera extrêmement importante et significative des données initiales : Elle devra absolument être interprétée selon les termes du métier qui prête ses données.
On peut également envisager que les individus et les variables aient des rôles interchangeables : c'est le cas d'un sondage d'opinion où des personnes sont invitées à exprimer leurs préférences sur un catalogue de produits, de personnalités, etc...Alors les individus peuvent être aussi bien les personnes que les entrées du catalogue; cette symétrie des rôles conduit à introduire une hypothèse dans le calcul, aboutissant à des formules spécifiques regroupées sous le nom d'Analyse Factorielle des Correspondances - La ressemblance de l'analyse de données et du Data Mining
- Ici il est important de marquer un temps d'arrêt dans la présentation du modèle sophistiqué de l'analyse de données. En effet, le data mining reprend ce modèle, et exploitera l'algorithme de réduction des variables mais sans tenir compte de la partie du modèle qui suit. Il y a divergence entre les deux techniques, même si l'on pourrait très bien envisager un métissage des deux[2]. Les anglosaxons mettent plus l'accent sur le statut des variables étudiées, c'est-à-dire que certaines colonnes seront choisies et considérées comme résultats d'une boîte noire hypothétique, tandis que les colonnes restantes seront considérées comme les entrées de cette même boîte noire. L'important est d'expliciter cette boîte noire, c'est la problématique des Machines à apprentissage. Les variables/colonnes de sortie sont appelées "variables expliquées", tandis que les variables/colonnes d'entrée sont appelées "variables explicatives". Ainsi le logiciel Yale/RapidMiner fait-il la distinction entre des variables régulières (explicatives), des variables Id (identifiant d'un individu), des variables label et cluster (appartenance d'un individu à un groupe), la variable label étant toujours la variable expliquée; bien entendu le statut des variables est manipulable sur l'ensemble des colonnes.
modèle mécanique
Le professeur Benzecri voulait donner un éclairage particulier sur le rôle des individus dans une table d'analyse. Ainsi, selon la méthode de recueil des données statistiques sur le terrain, on pourrait considérer que chaque individu est plus ou moins fiable : c'est une problématique que l'on retrouve par exemple en journalisme, en recherche universitaire ou en investigation, lorsque différentes sources sont plus ou moins fiables. On va alors affecter un nombre complémentaire à chaque individu/rangée de la table, qui peut être un pourcentage (note de fiabilité) ou un nombre sans limites particulières (nombre d'observations de l'individu) par exemple.En utilisant de tels nombres, la théorie montre que l'on modifie l'outil "métrique" dont nous avons parlé plus haut, ainsi que l'emploi de l'indicateur de variance résiduelle.
La pondération des individus
Cette partie, non-reprise en data mining, consiste à doter chaque individu (donc chaque rangée de la table d'analyse) d'un nombre réel appelé "poids"[3]. L'idée était de pousser l'analogie jusqu'à reprendre des éléments de la mécanique traditionnelle (mécanique du point) et essayer de repérer le pendant d'un élément du modèle mécanique dans la liste des éléments du modèle algébrique. Qu'est-ce qui, dans ma table, joue le rôle d'une masse, d'une distance, d'un centre de gravité, d'une inertie, d'une force ou d'un mouvement ? Les deux derniers éléments appartiennent à une branche de la mécanique appelée "dynamique" alors que les premiers ont plus un rôle descriptif, permettant de proportionner entre eux les phénomènes dynamiques. Il s'agit de la partie "cinétique" de la mécanique.Concrètement :
- Le terme "poids" est abusif en référence au vocabulaire des mécaniciens, car cela désigne une force, alors que la nature du concept employé par Benzécri est bien celui d'une masse.
- En mécanique, la masse se mesure en kilogrammes, alors que dans l'analyse de données, c'est un simple nombre sans dimensions. Après emploi des poids dans les équations sur la table, on obtient des résultats relativement simples d'expression, peu intuitifs mais dont l'explication graphique est intéressante. Les calculs eux-mêmes obligent à utiliser des matrice de poids qui compliquent singulièrement le travail, mais dont la difficulté s'estompe à l'obtention du résultat.
Voici les concepts spécifiques du modèle mécanique :
- Les poids
- Le nuage
- Le barycentre
- L'origine
- L'inertie (par rapport à un objet).
Le nuage est l'association des individus, exprimés sous forme de vecteurs, et de leurs poids respectifs. L'image à garder est celle d'un bouquet de roses, chaque rose ayant une tige spécifique (longueur, forme, nombre d'épines) et une fleur spécifique (taille de la fleur = poids).

L'origine est le point depuis lequel il est possible de convertir les individus en vecteurs avant de les intégrer dans le nuage. Chaque individu est assimilable à un point, pour le transformer en vecteur il faut le comparer à l'origine, comme pour un tracé au cordeau. L'origine du "bouquet" serait l'extrémité nue des tiges, toutes reliées entre elles. L'origine et le barycentre sont différents, et pour chaque méthode d'analyse de données ainsi que chaque nuage de données disponibles, il faudra vérifier si d'aventure ces deux points étaient confondus. Dans le cas du bouquet de roses, l'origine et le barycentre seraient confondus si le bouquet avait plutôt la forme d'une sphère.
L'Inertie en mécanique
L'inertie est un concept plus délicat à appréhender; dans le cas du bouquet, supposons que nous accrochions de manière rigide, encastrée comme disent les mécaniciens, l'extrémité (l'origine) du bouquet sur un arbre de sortie d'un moteur; mettons en route le moteur : Par la force centrifuge du bouquet (s'il lui reste encore des pétales[5]), quelle force subit l'axe moteur ? Cette force va dépendre en fait de deux facteurs :- La masse des roses
- La manière dont le bouquet est encastré sur l'axe, à savoir son inclinaison : dans le prolongement de l'axe, en "Té" par rapport à l'axe, ou entre les deux, formant un angle ?
L'Inertie en analyse de données
En mécanique, l'unité de mesure d'une inertie est celle d'une masse multipliée par le carré d'une distance : Ce sont donc des kilogrammes-mètre carré (et non desEn analyse de données, c'est un peu plus compliqué :
- Les poids sont des nombres sans dimension
- Les distances sont également sans dimension. Ce sont en fait des scalaires (voir note 4) qui permettent de mesurer "l'éloignement" de deux rangées ou de deux colonnes entre elles. Dans le cas de la comparaison de deux colonnes, c'est encore plus délicat : Que signifie la comparaison entre des valeurs de l'âge et de la taille des personnes interrogées ? On est obligé de ramener ces valeurs à des pourcentages pour pouvoir comparer ces grandeurs entre elles : c'est l'opération de normalisation des colonnes. Alors débarrassées de leurs unités, les colonnes sont distantes entre elles d'un certain scalaire sans dimension
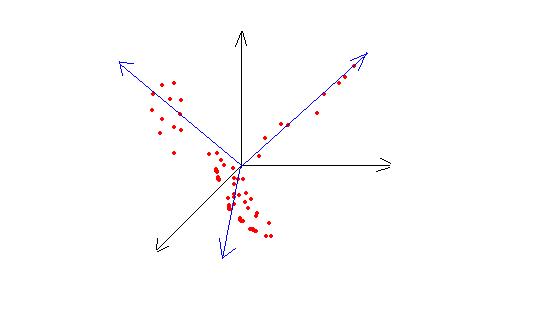
En outre, et cela différentie l'inertie d'une simple variance, la mesure de dispersion qu'apporte l'inertie va dépendre de la direction dans laquelle on considère cette dispersion : C'est exactement le cas du bouquet de roses et de son inclinaison par rapport à l'axe moteur. Ainsi pourra-t-on qualifier plus ou moins grossièrement la forme du nuage et de ses composantes. Il sera alors possible de trouver des axes privilégiés le long des "concentrations d'inertie", remplaçant les colonnes initiales de coordonnées, selon lesquels lire les individus : C'est le principe de l'Analyse par Composantes Principales.
L'inertie peut donc être considérée en analyse de données comme une variance tenant compte de la géométrie et de l'orientation du nuage. Pour représenter un tel concept, le professeur Benzecri a utilisé le modèle matriciel qu'il avait précédemment mis en place :
- L'inertie se calcule sur un objet, par rapport à un autre et dépend des poids des individus
- L'inertie s'écrit donc I=fonction(A,M,B) avec A dont on mesure l'inertie (un point, un nuage, etc...), B l'objet de référence (un point, un axe, etc...) et M la matrice d'inertie, un tableau de chiffres dont les coefficients sont calculés à partir des poids du nuage d'individus et uniquement à partir de ces poids.
- Passage d'un espace à l'autre (intitulés <> valeurs)
- Au sein d'un espace vectoriel, mesure de dispersion et de forme d'un nuage
- En classification descendante hiérarchique (CDH), qui produit un arbre
- Dans l'algorithme des "nuées dynamiques" ou "k-means" qui produit un "cluster plat", c'est-à-dire une liste
Les méthodes
Les différentes méthodes qu'a développées le professeur Benzecri tiennent compte de la position du barycentre par rapport à l'origine.L'Analyse par Composantes Principales
Cette méthode part du principe que le barycentre et l'origine sont distincts. L'idée de base était que les décideurs politiques, économiques et administratifs se voyaient remettre des rapports de synthèse leur présentant la mesure de différents phénomènes sous forme de statistiques. Ces rapports présentaient généralement le phénomène mesuré en histogrammes, "camemberts" et tableaux reflétant la part d'influence de différents facteurs sur le phénomène.Ces rapports faisaient des pages, étaient volumineux et ne permettaient d'avoir une vue synthétique de la situation au premier coup d'oeil. En effet, si un phénomène dépendait d'une dizaine de facteurs, il fallait alors dessiner l'histogramme du phénomène face au premier facteur, puis au second, puis au troisième...Ensuite il fallait présenter la part du deuxième facteur comparée à celle du premier facteur dans le phénomène, etc...La combinatoire des facteurs pouvait rapidement devenir infernale, et peut-être avez vous connu ces rapports statistiques qui s'étirent sur des pages sans fin ?
Cette problématique de présentation des rapports, sans d'ailleurs tenir compte du temps de recueil et d'assemblage des données, a été appelée le reporting, une des briques de base de la Business Intelligence. On y répond de deux manières :
- Soit par un arbre de segmentation, ou "Drill Down" : l'idée est "d'empiler" des restrictions sur les valeurs observées des facteurs. L'empilement des conditions sert alors de requête sur la base de données et est organisée selon un arbre. "Quel est l'ensemble des individus qui a entre 20 et 30 ans ?"; puis "Sur cet ensemble, combien gagnent entre deux et trois fois le SMIC ?"; puis "Sur cet ensemble...".
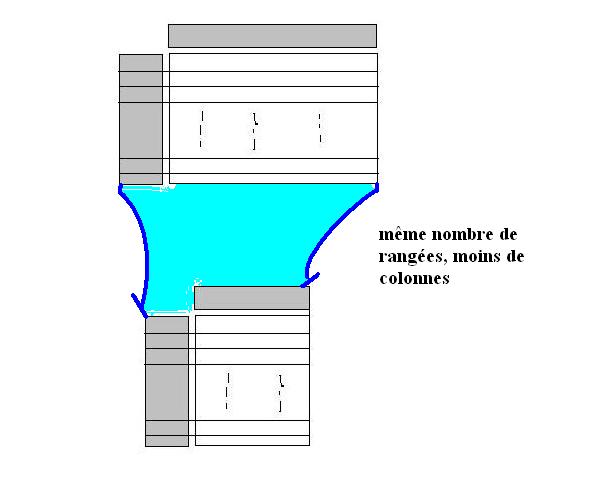
- Soit par une réduction de variables, ce qui permet de réduire considérablement le nombre de graphiques statistiques en ne se focalisant que sur l'essentiel
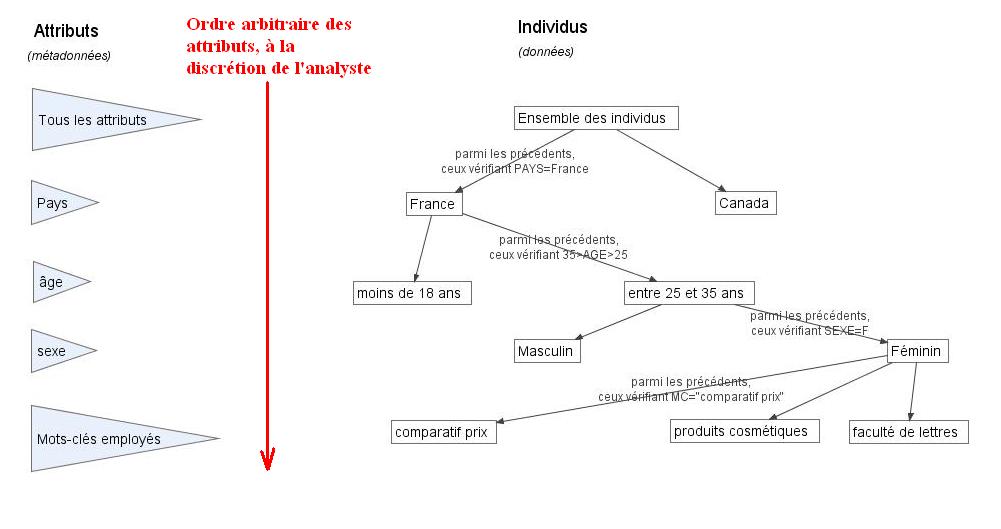 |
 |
| arbre de segmentation[10] : Les attributs-colonnes sont les niveaux, les individus-rangées sont les branches |
le principe de réduction d'une table : A l'arrivée, il y a moins d'attributs qu'au départ les nouveaux attributs sont différents des anciens |
Introduction : l'ACP en sciences humaines
Remplissez ce questionnaire de 20 questions en cochant les cases. Puis reportez-vous en page finale où le tableau vous permettra de calculer vos points. Enfin, en fonction de ce nombre, lisez le paragraphe qui correspond : "Vous êtes ceci, vous devriez faire cela..."Que ce soit à la plage en lisant le dernier psycho-test d'un magazine, ou lors d'un entretien d'embauche, nous avons tous eu droit un jour à ces satanés tests qui commencent comme un sondage et finissent comme une leçon de morale, parfois amère !
Le principe est pourtant simple : Sur les données que représentent les cases que vous cochez, les concepteurs du test ont préalablement effectué une réduction de variables, et le tableau de calcul est un classificateur. De mon avis personnel, le système est plus que rudimentaire et n'intègre pas de souplesse pour s'adapter par apprentissage...
Pour vous donner un exemple de la réduction de données effectuée à la conception du test, je souhaite vous parler d'un test dit "du socio-profil"; après avoir rempli un questionnaire sur la manière dont vous avez de parler aux autres, de gérer les problèmes, le tableau de calcul final vous classe dans une image, un plan à deux axes principaux :
- L'axe que j'appelle de la "vie sociale" : renfermé ou exhubérant ?
- L'axe que j'appelle de "l'initiative" : suivre le mouvement ou innover ?
- Promouvant : Vous prenez l'initiative et vous savez communiquer. C'est dans cette catégorie que les recruteurs cherchent les futurs cadres
- Facilitant : Vous communiquez facilement et vous suivez le mouvement. Les cadres s'appuient sur cette catégorie pour mener leurs projets
- Contrôlant : Vous prenez l'initiative mais vous ne communiquez que rudimentairement. Ce sont les hommes pressés, qui ont horreur des grands discours et ont des décisions à prendre "rapidement"
- Analysant : Vous parlez peu et suivez le mouvement. Ce profil est surnommé "gardien du temple"
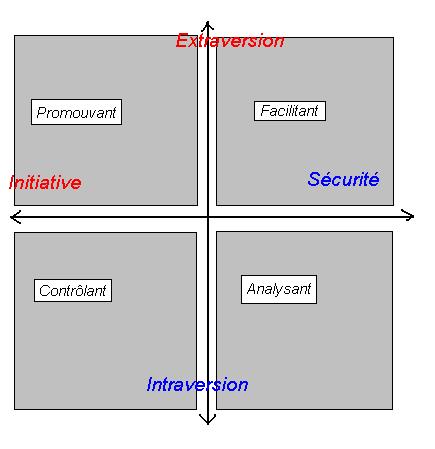
Il faut d'abord considérer qu'ils ont d'abord créé un questionnaire dont le nombre de questions a été supérieur à celui qui vous a été présenté. Chaque question est à considérer comme une variable
Après avoir enquêté auprès d'un nombre signifiant de personnes (au minimum une trentaine), ils ont utilisé une Analyse par Composantes Principales pour détecter d'éventuelles tendances dont ils ignoraient l'existence. L'ACP fonctionnant sur la base de l'Inertie, chaque nouvelle variable (appelée "axe principal") est affectée d'un pourcentage représentant son importance dans le lot de données : Il s'agit directement d'un ratio d'Inertie à l'Inertie totale. Ainsi ils ont sélectionné les deux premiers axes, dont l'Inertie cumulée devait dépasser les 60%, expliquant donc 60% de l'information contenue dans les résultats d'enquête. On passe ainsi d'une vingtaine de questions, donc d'une vingtaine de variables, à deux axes soit deux variables.
À partir de ces axes, il est possible de mesurer à rebours la contribution de chaque question à l'un des axes, permettant ainsi de sélectionner les questions les plus importantes.
Une fois les questions choisies, ils réutilisent l'ACP pour obtenir le lot final de questions, ainsi que les formules matricielles de passage dont nous avons parlé plus haut.
La création de la mosaïque suit alors la méthode de Johnson pour faire apparaître un jeu naturel de catégories : C'est à ce moment qu'est déterminé le nombre de "paragraphes de conclusion".
Enfin, pour déterminer l'appartenance d'un individu à l'une de ces catégories, ils vont mettre au point un "classificateur" dont la nature dépendra de la qualité de l'ACP effectuée auparavant : Une ACP peut extraire pratiquement autant d'axes que de variables initiales et plus le classificateur prendra en compte de nombreux axes, plus la décision de classification sera juste. En comparant le nombre de questions d'un test aux deux axes principaux, et sous réserve de connaître l'inertie des deux axes, vous pouvez donc avoir une idée de la fiabilité du jugement porté...[6]
Je voudrais vous citer une histoire qui m'est personnellement arrivée, et qui est éclairante sur la manière d'utiliser ces tests :
Je travaillais depuis trois ans dans un service, où j'avais eu le temps de faire mes preuves. Au rythme effréné des dossiers à traiter, j'avais acquis de l'expérience et étais connu de tout le service comme un ingénieur original, efficace et affable. Puis un nouveau chef arriva : Parlant beaucoup de management, il me proposa le désormais connu test du socioprofil. Je ne savais pas répondre à la moitié des questions, et dès que j'hésitais il répondait à ma place en m'expliquant qu'on est toujours mieux jugé par les autres; puis dans la foulée, il fit le test lui-même...Résultat du test : je me suis retrouvé "analysant", "renfermé et cherchant la sécurité" tandis que lui se retrouvait "promouvant" !!A l'évidence, la démarche était perverse car que se serait-il passé si à tout hasard le test montrait que j'étais "promouvant" et lui "analysant" ? J'en ai déduis :
- Un supérieur hiérarchique qui vous propose un test n'est jamais désintéressé. Il veut peut-être vous montrer que c'est lui le chef. La situation peut devenir infernale si les deux savent que l'un des deux est objectivement inutile
- Un test devrait toujours être effectué et analysé par des professionnels de la sociologie et de la psychologie, dont la position au sein du groupe doit être découplée de la hiérarchie
- De manière générale, un test ne devrait jamais être manipulé par une personne à laquelle vous êtes liés d'une manière ou d'une autre, socialement, familialement ou affectivement. Cela peut donner la terrible illusion de vérité scientifique à ce qui n'est que la projection d'un fantasme
Un test comportemental ne peut donc qualifier qu'une attitude, un comportement au sein d'un groupe et donc un phénomène de circonstance à prendre en compte dans la gestion d'un groupe, et non un jugement de valeur sur la personnalité d'untel ou untel...
Le mieux est encore de travailler au cas par cas : Une analyse de données qui serait effectuée in vitro, dégageant des axes principaux, des catégories et des classificateurs spécifiques au contexte a bien plus de valeur et de pertinence que ces tests de magazine. C'est en cela que je préfère de loin la démarche du "data miner", fondée sur un apprentissage et une exploration empirique des données.
Imaginez donc un curieux test sociologique ou psychologique dans lequel vous pourriez notifier votre accord ou désaccord sur le résultat : Le tableau de calcul se modifierait lentement et de lui-même en fonction des votes de chacun...Ça, c'est du vrai test, de l'analyse de données dans toute sa splendeur !
De manière générale, chaque fois que vous verrez un schéma de principe où deux axes en croix supportent un nuage de points ou une mosaïque, vous pourrez soupçonner l'emploi d'une ACP sur des données statistiques. Ainsi est-ce le cas de cette analyse socio-économique qui a été menée sur plusieurs pays dans le monde pour étudier le lien entre les valeurs morales dans un groupe et sa situation économique. Les résultats sont ici : L'étude des valeurs et des sociétés. L'étude ne précise pas si ce sont les valeurs qui sont la cause ou la conséquence de la situation économique. Pour cela, il faudrait analyser :
- Les classes cachées (méthode de Lazarsfeld, etc...) : découvrir des phénomènes intermédiaires, plutôt que de déduire que l'un entraîne l'autre
- Les règles d'association : Elles orientent le lien, et donnent une bonne idée du sens de la causalité (qui est cause, qui est effet ?)
A l'inverse et à titre personnel, je m'interroge sur la motivation réelle des clergés et des chefs spirituels à souhaiter un retour au dépouillement, à "l'ordre" et à la religion collective dans les sociétés occidentales...
Le fonctionnement de l'ACP
Comme vous commencez probablement à vous en douter, la plupart du système théorique de J.P. Benzecri va nous permettre de comprendre le fonctionnement de l'Analyse par Composantes Principales. Si l'analyse de données met l'accent sur cette méthode particulièrement populaire, il faut savoir qu'il existe d'autres techniques de réduction, produisant des résultats différents, avec autant d'interprétations différentes.Dans tous les cas, il faut considérer qu'une technique de réduction a pour but de compresser l'information contenue dans les colonnes : Pourquoi utiliser une vingtaine de colonnes pour représenter des individus (âge, date, poids, sexe, profession, longitude, latitude, salaire, etc...), alors que trois colonnes judicieusement choisies peuvent représenter de 70 à 90% de l'information contenue au départ ? Qui plus est, une fois que l'on a calculé les composantes principales et exprimé les nouvelles coordonnées des individus sur ces composantes, les axes sont sujet à interprétation et peuvent représenter :
- Des axes thématiques
- Des indices pertinents permettant de consolider des données financières
- Des indices de mesure de comportements. Il m'est personnellement arrivé de détecter un comportement de navigation lié à la langue d'un visiteur sur ce même site, après avoir utilisé une technique cousine de l'ACP
- Dans le cas de la lexicométrie, je ne compte plus le nombre de fois où l'ACP me permet d'évaluer les thèmes de mes pages. Le plus amusant, ce que c'est moi qui rédige mes pages, et pourtant je ne vois pas certains thèmes parce qu'ils font partie de mes habitudes intellectuelles. C'est alors un précieux auxiliaire en référencement
Pour reprendre ce qui a été déjà écrit, le principe de l'ACP consiste à :
- modifier les intitulés des colonnes d'un tableau, pour qu'ils soient moins nombreux et plus discriminants,
- ainsi qu'à recalculer les valeurs de chaque individu pour chaque nouvelle colonne.
Pour construire la matrice de corrélation des colonnes, il suffit d'appliquer le modèle vecteur/dual de Benzécri pour obtenir son expression :
- La matrice d'Inertie s'écrit comme un produit scalaire entre les colonnes deux-à-deux
- Le modèle dual établit que le produit se fait sur les valeurs et non sur les intitulés, mais que le résultat s'interprète sur les intitulés
- La forme du produit scalaire permet d'établir que pour deux colonnes de valeurs X et Y, (X"scalaire"Y) devient la covariance entre X et Y, tandis que (X"scalaire"X) devient la variance de X
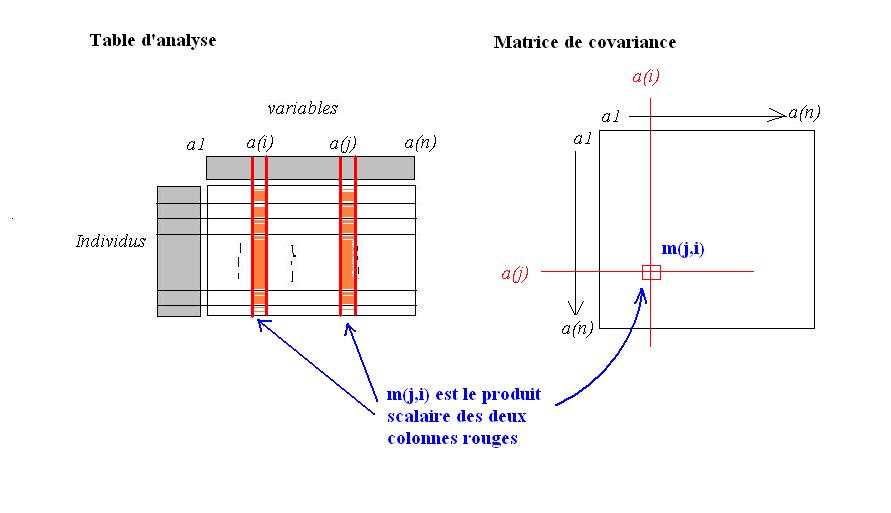
La matrice d'Inertie du nuage est de facto la matrice de covariance des attributs deux-à-deux
Avant toute opération d'ACP, il faut normaliser les colonnes de manière à ce qu'elles soient débarrassées des unités physiques de mesure employées et des ordres de grandeur propre à chaque colonneLa réduction du nombre de colonnes revient dès lors à produire un nombre restreint d'axes signifiants, mais les calculs montrent que ces différents axes n'ont pas la même importance. Ces mêmes formules de calcul permettent d'établir un coefficient d'importance pour chaque axe, qui servira à classer les axes entre eux mais aussi à évaluer l'importance de l'information que chacun d'eux représente. Ce coefficient est un pourcentage, appelé pourcentage d'inertie expliquée et représente en quelque sorte le taux de compression des variables initiales.
Ainsi, si un axe possède un pourcentage d'inertie expliquée de 60%, autant vous dire qu'il doit être analysé et interprété sous toutes les coutures. Si de plus, au départ, nous avions une vingtaine de variables, cela signifie que l'axe représente en partie 60% d'entre elles soit environ 12 variables !! C'est là toute la puissance de l'ACP...
L'autre intérêt de l'ACP en particulier, et des méthodes de réduction de dimensions en général est qu'il est mal aisé de visualiser des individus possédant plus de quatre coordonnées :
- Pour deux variables, on se sert d'une image plane
- Pour trois variables, on se sert d'une image en perspective dans un cube quadrillé
- Pour quatre variables, on se sert soit d'une image "bulle"[8], soit d'une perspective où les points sont colorés
- On tient compte du modèle vectoriel de Benzécri, où les intitulés et les valeurs ont des rôles symétriques
- Une image de points de valeurs, avec les intitulés tracés par des axes est une représentation dans l'espace des valeurs[9]
- Une image de points d'intitulés, avec les valeurs tracées par des axes est une représentation dans l'espace dual des valeurs
- Une image de points de valeurs et d'intitulés, avec des symboles différents pour les deux est appelée représentation hybride
La réduction de dimensions, en l'occurrence l'ACP, permet d'expliquer des connaissances liées au métier mais aussi permet de faciliter la visualisation des données et de comprendre leur structureLe seul problème avec l'ACP est que c'est un algorithme particulièrement gourmand en temps de calcul lorsqu'appliqué à des tables de data mining faisant plusieurs dizaines voire plusieurs centaines d'attributs. On applique alors une version "rapide" de l'algorithme en utilisant un réseau de neurones artificiels qui mime la séquence de calcul de l'ACP matricielle. Un tel algorithme, appelé "Generalized Hebbian Algorithm" (GHA) possède toutefois un défaut majeur : La variance expliquée pour chaque axe est estimée, elle n'est pas exacte. De plus, on ne peut pas le faire travailler à seuil de variance fixé : Avec l'ACP traditionnelle, on fixe une variance expliquée à 80%, puis l'algorithme calcule autant d'axes principaux que nécessaires tant que la somme des inerties estimées n'atteint pas ce seuil.
Approches probabilistes et statistiques
L'analyse de données, et son approche américaine le "data mining", sont en constante évolution. Ce ne sont pas des connaissances figées, elles suivent le mouvement de la recherche scientifique à mi-chemin entre :- Les sciences humaines
- Les sciences financières
- Les mathématiques
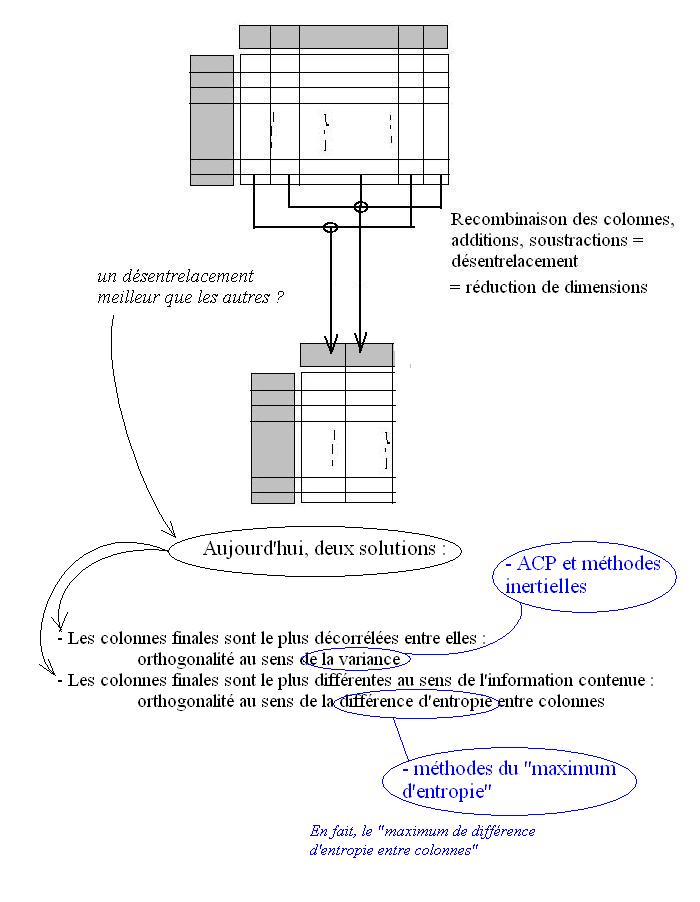
Ainsi le comportement de l'ACP a-t-il été repris pour s'étendre à la réduction de dimensions. L'idée d'une réduction est la suivante :
- On part d'une table de départ
- On veut aboutir à une table d'arrivée, avec moins de colonnes
- Pour cela, on utilise des formules de calculs qui recombinent les valeurs des colonnes entre elles
- Ces formules sont du type : "colonne d'arrivée numéro P" = 5 x "colonne de départ numéro 10" moins 3 x "colonne de départ numéro 4"
- Ces formules sont donc complètement résumées par la suite de leurs coefficients (5, -3) et les numéros des colonnes auxquelles on applique ces coefficients (10, 4)
- L'objet hybride {(5,-3),(10,4)} peut alors être choisi (on change les valeurs) de manière à régler l'effet sur les colonnes d'arrivée
- Pour mesurer cet effet, et donc faire les bon choix, on compare les colonnes d'arrivée entre elles
L'emploi de l'inertie étant le premier critère historique, il y en a un autre qui reproduit plus fidèlement la représentation de "l'originalité des colonnes", mais qui aboutit à des formules et des résultats différents : C'est l'entropie, et toutes les approches probabilistes qui en découlent.
En gros, l'entropie, c'est ce qui est original, ce qui n'est pas prévu. La puissance de cette approche est telle qu'elle ne nécessite plus de modèle mathématique a priori : Vous faites tourner les algorithmes sur des données, et il vous dit tout ce qu'il y a dedans, de manière distincte ! De plus, comme c'est une approche s'appuyant sur des probabilités, on peut la faire tourner sur un très faible nombre de données...
- ACP
- AFC
- GHA
- SVD
- ICA
- Carte de Kohonen
- Le calcul de l'entropie n'étant pas accessible directement, on utilise une formule réglable à souhait, dite de "negentropie". Elle fait intervenir des fonctions auxiliaires, que l'on retrouve dans les réseaux de neurones
- Le bon apprentissage justement d'un réseau de neurones permet de fournir des données dont l'inter-entropie est naturellement maximisée
- La maximisation de l'entropie peut être estimée (piètrement) par un indicateur statistique du 4ème ordre, le kurtosis, qui mesure la proximité d'un phénomène à un hasard naturel, dit "gaussien"
- La structure de ces algorithmes se rapproche des réseaux de neurones, qui ont la vertu d'être les algorithmes structurellement les plus rapides, et de loin
Il s'agit d'un algorithme particulièrement intéressant, puisqu'il répond au problème de la "cocktail party". Imaginez le salon d'un notable local, ouvert sur les jardins...C'est un soir, et tous les invités sont présents pour ces mondanités. Tout le monde discute, et de petits groupes se sont formés, le verre à la main...
Un petit malin a mis des microphones partout. Il sait combien il y a de micros, mais :
- Il ne sait pas combien il y a d'invités
- Il ne sait pas comment ils sont placés, dès lors que les groupes se font et se défont
- Il ne connaît pas précisément les caractéristiques de ses micros, notamment dans quelle direction ils enregistrent le mieux
- Retrouver combien il y a de personnes qui causent
- Séparer les bandes sonores de chacune des voix des personnes, pour savoir ce qui se dit
Et tout cela uniquement sur des considérations d'entropie entre les voix...!!
D'autres applications tout aussi intéressantes ont été rapidement trouvées :
- En médecine du cerveau (?) : On pose des électrodes sur le crâne d'un patient, et on recueille des courants électriques diffus, chacun représentant un entrelacement des différentes activités du cerveau. Un petit coup d'ICA, et l'on voit apparaître, comme par miracle, les différents diagrammes d'activité de chacune des zones du cerveau !!
- En commerce : Le chiffre d'affaires est indirectement conditionné par un ensemble de phénomènes extérieurs (conjoncture, calendrier annuel des consommateurs et des fêtes, problèmes de logistique divers...). L'idée est de récupérer les listes d'écritures comptables de caisse enregistreuse sur chaque point de vente (les points de ventes étant dispersés sur le territoire) et de considérer chacun de ces listings comme un "microphone" de cocktail party. Le désentrelacement par ICA révèle notamment l'impact des fêtes et jours fériés, d'où l'introduction de "fêtes auxiliaires" comme Halloween et la Saint-Valentin
L'Analyse Factorielle des Correspondances
Le principe
L'Analyse Factorielle des Correspondances, en abrégé AFC, est ce qui a valu la célébrité au professeur Benzécri dont j'ai beaucoup parlé dans les lignes précédentes. Curieusement, les travaux sur l'ACP ou l'ICA ne sont pas de lui. En revanche, il a reformulé ces travaux dans son modèle matriciel, et introduit la méthode que je vais exposer, donnant un sentiment d'unité à tous ces outils. On parlera dès lors d'analyse des données si l'on se place dans ce modèle matriciel pour y déployer toutes ces méthodes.L'AFC est une méthode particulière car elle ne s'appuie pas sur l'analyse d'un tableau de réalisations statistiques, tel que le serait un journal comptable ou un historique de fonctionnement d'une machine. Pour pouvoir appliquer l'AFC, il faut d'abord effectuer un comptage, une réorganisation des valeurs pour compter leurs effectifs : Il s'agit d'écrire un Tableau de contingence[11]. Imaginons un sondage (car la méthode y est recommandée) où le questionnaire à remplir est composé de deux séries de questions :
- La première série vise à savoir qui vous êtes (âge, profession, etc...)
- La deuxième série vise à savoir qui vous voteriez, ou qui vous avez voté (choix dans un catalogue de personnalités, de partis, etc...)
L'idée est de prendre et de se fixer deux colonnes à mettre en "vis-à-vis", en correspondance (d'où le nom de la méthode). Prenons par exemple la "profession" et "l'intention de vote au second tour". On va recréer un tableau à partir de la liste des sondés et de leurs réponses, où ce nouveau tableau aura en ligne les valeurs de la colonne "profession" et en colonne "intentions de vote". Il me semble (à vérifier) qu'une telle fonctionnalité de ventilation existe sous Excel avec les tableaux croisés dynamiques. Dans ce nouveau genre de tableau, chaque case contient le nombre d'individus, la fraction de rangées du tableau de départ, qui correspond aux critères de valeurs sur les colonnes.
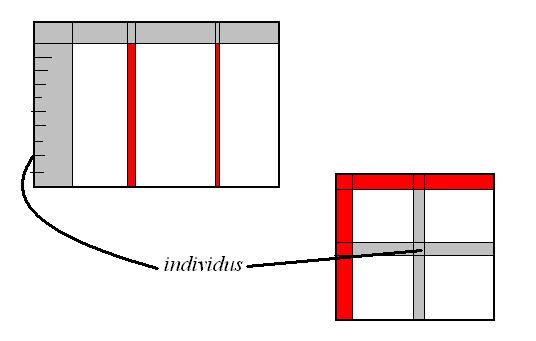
La deuxième remarque, proche de la première, est que les valeurs comptées dans chacune des cellules ont encore plus de pertinence si elles sont exprimées sous forme de pourcentages :
- Pour un parti politique donné, combien de votants ont donné leurs voix, et qui sont-ils (lecture en ligne)
- Pour une classe sociale donnée, comment se répartissent les votes ? (lecture en colonne)
- Un investisseur achète sur plusieurs valeurs en Bourse : On parle de portefeuille des actions, qu'on lira en colonne
- Une entreprise voit son capital réparti entre plusieurs actionnaires : On parle de répartition du capital, à lire en ligne
L'idée majeure de l'AFC est d'effectuer une ACP particulière sur le tableau de contingence comme si ce tableau était une table d'analyse classique, munie du modèle algébrique de Benzécri. Si le tableau de contingence représente un entrelacement de valeurs croisées, l'AFC désentrelace ce tableau pour regrouper les individus et modifier les critères de mesure afin d'avoir une vue claire de la situation et comprendre les forces en présence.
Toutefois, la nature même du tableau de contingence conduit à modifier la métrique utilisée lors de l'ACP. La métrique introduite pour créer le concept d'Inertie était une simple distance euclidienne pondérée. Comme il s'agit de mesurer des distances entre des pourcentages, une métrique plus adaptée est la métrique du "Khi-2". Ainsi l'AFC n'est rien d'autre que :
Une Analyse par Composantes Principales, effectuée sur un tableau de contingences, avec une métrique du Khi-2. Rien de plus. l'AFC permet de répondre à la question "qui fait quoi" de manière lisibleEn revanche, l'examen des propriétés de cette opération montre que si l'on analyse le tableau de contingence d'une part, et son "tableau symétrique" (transposé) d'autre part, on obtient les mêmes valeurs propres (quantité d'information représentée par chaque nouvel axe) mais des vecteurs propres différents (signification de chaque axe). Les calculs pour y arriver sont également simplifiés...
Les techniques d'interprétation et de visualisation sont alors les mêmes qu'en ACP, avec des représentations hybrides par exemple, mêlant les variables et leurs valeurs, ce qui permet d'expliquer le rôle des variables de départ et la position des individus dans la nouvelle mosaïque calculée par AFC.
Les extensions et applications
J'ai parlé tout-à-l'heure d'un tableau de contingences opposant la classe sociale d'un votant à ce qu'il vote effectivement. Ce groupement des critères de formulaire en deux est fondamental, puisqu'alors vous comprendrez que toute analyse sociologique d'une population peut se ramener, à un moment ou un autre, à un tableau de contingence; ainsi, dans les machineries sur Internet qui gèrent les groupements de bookmarks, ou le partage de fichiers (logiciels, musique, etc...), ces machines utilisent probablement et entre autres l'AFC pour découper la population des inscrits en classes de comportement, reliant ce que les abonnés sont (profil personnel, "avatar", etc..) à ce qu'ils choisissent (centres d'intérêt, signets et marque-pages). C'est ainsi que de telles machines peuvent s'adapter et faire des recommendations pertinentes, comme celles que je cite sur la page "musique". Cette technique est souvent appelée "scoring", mais le terme est abusif puisqu'il est confondu avec des classificateurs, qui sont plus du data mining. Un exemple de "scoring" : StumbleUpon.De manière générale, il existe d'autres analyses factorielles, d'autres méthodes qui diffèrent de l'AFC par le résultat atteint et le type de tableaux qu'elles traitent : Elles s'appuient toujours sur le principe de la diagonalisation et l'utilisation d'une métrique spécifique au type de tableau. Ainsi nous avons :
- L'Analyse des Correspondances Multiples (ACM)
- Cette méthode vise à consolider différents systèmes de classification qui ne coïncident pas entre eux. Malgré son nom, elle n'a que peu de ressemblances avec l'AFC. L'idée est que si une centaine d'individus est classifié par un critère C1 dans 5 catégories différentes, et en même temps par un autre critère C2 dans 3 catégories, C1 et C2 n'ont a priori rien à voir. L'ACM peut alors dresser une carte de répartition mixte des individus et des catégories de C1 et C2 en même temps. Cela permet d'aboutir à une comparaison explicative de C1 vis-à-vis de C2 et réciproquement. Astucieux !!
- L'Analyse Factorielle d'un Tableau de Dissimilarités (AFTD)
- Un tableau de dissimilarités peut être lié par certaines relations à un tableau de similarités et à un tableau de distances, mais sous certaines conditions. L'idée est qu'on peut facilement construire un tableau de dissimilarités, mais passer à un tableau de distances et donc s'acheminer vers les méthodes de "clusters" et autres classifications non-supervisées nécessite un effort de vérification que permet justement l'AFTD Mon opinion est que ces analyses sont appelées factorielles parce qu'elles s'appuient sur des tableaux de contingence et dérivés (tableau disjonctif, tableaux de distances,etc...) qui visent à "comparer des choses entre elles" et non décrire de manière comptable et analytique un ensemble d'individus. Par la relative symétrie de rôles des lignes et des colonnes, le modèle complet de Benzécri se justifie pleinement, alors qu'une table d'analyse se contentera du modèle "data mining".
- Les méthodes françaises d'analyse de données, ou méthodes dites "factorielles", s'appliquent essentiellement sur des données consolidées dans les bases OLAP
- Un "data mining" irréprochable, c'est-à-dire qui tiendrait compte du contexte, devrait toujours se faire en appui d'un système de "BI", mais en amont des bases OLAP, au niveau de l'entrepôt des données brutes
- La partie "non-supervisée" du data mining peut servir à construire le système de "BI", notamment les clusters pour la segmentation, et les règles d'association pour définir les axes d'hypercubes. Alors, au sein de ces hypercubes, des analyses factorielles seraient du plus bel effet !
- Comme en data-mining, il s'agit de munir chaque attribut d'un poids, ainsi dire si la durée d'un travail est plus importante que son prix ou réciproquement
- A la différence du data-mining, toute méthode d'analyse multicritères consomme en entrée une table de données (les lignes sont les objets à classer, les colonnes les critères selon lesquels on classe) et produit un graphe de surclassement donnant la préférence d'un objet sur l'autre au travers de chaque lien. Ce graphe doit être idéalement un arbre
- La différence entre arbre et graphe correspond à l'analyse des circuits fermés. Selon la manière dont est résolu ce problème, on peut avoir différentes moutures de méthodes d'analyse
- On pourrait imaginer contourner l'emploi de méthodes d'analyse multicritères par l'emploi de méthodes d'aggrégations de données, comme les "clusters" en data mining ou la méthode de "Johnson". Dans le livre sur l'analyse visuelle des données, j'ai ainsi pu constater l'emploi d'un combinat entre une méthode de "cluster plat" et une méthode d'arbre de recouvrement minimal faisant office à l'évidence d'analyse multicritères. L'idée est de dire que si plusieurs éléments se ressemblent, ils sont très différents d'autres éléments en termes de distance, ce qui constitue une base de classement.
- Les bases théoriques des méthodes d'analyse multicritères se retrouvent en data-mining pour les algorithmes "votés" : perceptron voté, régression votée, etc...
- Autres méthodes table/graphe : matrice distance (voir aussi méthode de Johnson), CRF et entités nommées
- Spécificité ELECTRE : applications
- En anglais, les "aggregates" correspondent aux aggrégats, c'est-à-dire à ces tableaux de synthèse, aux tables de contingence de l'AFC dans les bases "OLAP".
- En anglais, les "clusters" se traduisent par "grappes". C'est un terme que l'on retrouve aussi en informatique pour désigner un assemblage de machines ayant vocation à fournir de la puissance de calcul sur une machine virtuelle unifiée
- En français, "cluster analysis" pourrait se traduire par "analyse des grappes" ou "analyse des agglomérats". La notion de "conglomérat" a quelque chose de supervisé, planifié, piloté...
- L'analyse des agglomérats me permet de déterminer la structure intrinsèque d'une population. Cette structure se traduit par un jeu de tranches, comme par exemple les "tranches d'âge", les catégories socio-professionelles et autres...À la lumière de ces tranches, je peux critiquer et interpréter mes statistiques en toute sécurité
- Ce même système de tranches ou "segments" me permet de conduire des échantillonnages astucieux, dits "échantillonnages stratifiés", de mes données. La légendaire problématique de la puissance de calcul en analyse exploratoire est ainsi contournée.
- L'apppartenance d'un individu à une "tranche" ou à un "profil" permet non-seulement de cerner de manière astucieuse le rôle de chacune des variables explicatives, mais aussi permet d'introduire une notion de "domaine de validité d'un modèle" sous forme d'une variable explicative supplémentaire. Si je construis ultérieurement un modèle de décision ou d'estimation, il deviendra de facto un modèle composite, assemblé depuis les sous-modèles de chaque domaine ou profil. On s'achemine alors vers les machines à base d'instances, et on peut alors expliquer plus simplement le fonctionnement d'une régression logistique
- Introduire une mesure de distance mathématique entre les individus
- Elaborer un tableau de distances entre les individus deux-à-deux. S'il y a 5 individus, le tableau aura 5 lignes et 5 colonnes.
- La distance entre A et B est de facto la même qu'entre B et A. Le tableau n'est donc rempli qu'à moitié.
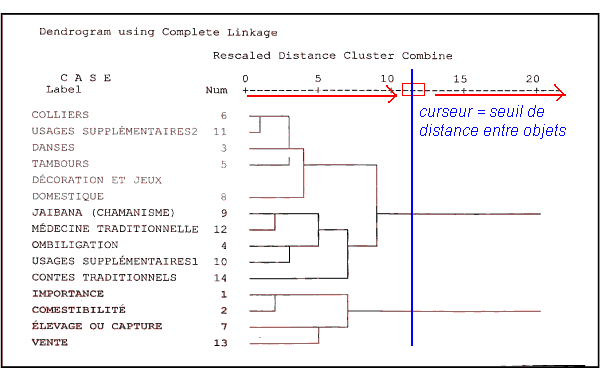
- On crée un curseur imaginaire le long d'une ligne, qui va de la plus petite distance du tableau à la plus grande.
- Ce curseur sert de seuil de regroupement. Lorsqu'il est au minimum, on a autant de groupes que d'individus. Lorsqu'il est au maximum, on a un seul groupe contenant tous les individus.
- A chaque passe, on augmente d'un cran le curseur : des individus et des groupes existants sont regroupés en groupes plus grands.
- Au final, le schéma qui décrit l'emboîtement des sous-groupes entre eux est un arbre, appelé "dendogramme".
- cette notion risque d'être modifiée à chaque niveau de profondeur de l'arbre
- La notion de distance, facilement théorisable en mathématiques fondamentales, peut très bien être incompatible de la nature des données. Cette vérification est typique de l'analyse factorielle des dissimilarités
- Similarité
- Dissimilarité
- Ultramétrique
- Hiérarchie indicée
- Bottom-up agglomerative clustering
- UPGMA
- K-means
- K-medoids
- KernelKmeans
- K-star
Or, typiquement, pour obtenir ces tableaux de contingence, il faut nécessairement aggréger les données, c'est-à-dire utiliser des statistiques descriptives de type "somme des individus", "moyenne des individus", etc...Cette opération est connue sous Excel et s'appelle le tableau croisé dynamique, qui se généralise à la notion d'hypercube. Une somme ou une moyenne d'individus est alors calculée pour certaines classes, et est appelée "aggrégat". Une base de données qui contient des hypercubes d'aggrégats possède une structure spécifique, dite "OLAP". C'est LA structure de base utilisée en Business Intelligence.
Vous constaterez alors de vous-mêmes que les méthodes dites "factorielles" s'appuient naturellement sur le contenu des aggrégats, puisqu'un hypercube de dimension 2 (un carré, en fait...) contenant des aggrégats de type "somme des individus" peut bien vite se ramener à un tableau de contingence après normalisation. En outre, les traditionnelles précautions d'emploi qu'exhibent les statisticiens à l'encontre des "data miners" sont généralement des valeurs soit de statistique descriptive, soit de segmentation, soit d'effectifs de classes, qui ne sont strictement rien d'autres que la bonne lecture des bases OLAP.
Conclusion :
Entre chiens et loups : les méthodes hybrides
Les méthodes qui suivent ne sont pas spécifiquement liées au "data mining" mais restent dans le giron de l'analyse de données. La différence entre les deux disciplines réside, nous l'avons vu, dans la différence des modèles, l'un se contentant d'un modèle algébrique, l'autre poussant jusqu'au modèle mécanique pour introduire la notion d'Inertie et les méthodes qui s'y rattachent. Là, le problème de modélisation se corse car ces méthodes manipulent en entrée une table de données et en sortie un graphe, et réciproquement. Reste à voir l'emploi et l'interprétation.L'analyse multicritères
L'analyse multicritères est un vocable qui est apparu essentiellement en France vers les années 1970, sous l'impulsion des travaux de plusieurs chercheurs de l'Université Paris Dauphine. Si vous avez plusieurs activités à effectuer, chacune d'elle étant caractérisée par plusieurs mesures, vous aurez probablement à les ranger les unes par rapport aux autres[12]. Lorsque chaque activité est par exemple mesurée par sa durée, il est très simple de les classer toutes par durée croissante. En revanche, lorsque chaque activité est mesurée par deux facteurs, voire plus et qui ne sont pas simultanément croissants ou décroissants, l'affaire devient nettement plus "coton".C'est tout le sujet de l'analyse multicritères. Je l'ai par ailleurs rangée dans la page "analyse de données", car ce n'est pas du data-mining, mais ça y ressemble :
Pour information, j'ai testé un tel problème lorsque j'ai choisi l'hébergeur de ce présent site parmi plusieurs, en m'appuyant sur le data-mining : l'idée est de filtrer les attributs d'une part (simplification de la liste des critères), d'aggréger les offres ressemblantes d'autre part (détection des types d'offres) pour construire une carte visuelle de même rôle que le graphe de surclassement. Le filtrage des attributs s'appuyait sur l'union de deux filtrats, l'un non-supervisé pour ne garder que les attributs qui distinguent les concurrents entre eux (variance des attributs) et l'autre sur l'ajout d'une "note de gueule" que l'analyse discriminante ("wrapper") permet d'objectiver et d'expliquer. Résultat surprenant : la qualité et le rapport qualité prix se trouvent exactement là où il n'y a pas de publicités "pop-up". Méthode ELECTRE : double critère : préférence et exclusion. Paris Dauphine, double mouture ELECTRE I et ELECTRE II
Produire un graphe à partir d'une table :
Insister sur les différents types de relation d'ordre : ordre total, ordre partiel, autres ? droite contre graphe
Schéma/galerie des différents types d'ordre.
L'analyse des proximités
Relations locales dans un graphe : déterminer le bon modèle vectoriel pour chaque noeud, et ses valeurs associées.La Classification Ascendante Hiérarchique
La méthode de Johnson
Dans cette partie, j'aborde un problème plus général que la simple méthode énoncée en titre, qui est celui de l'analyse non-supervisée des données statistiques. L'idée est de disposer d'une série d'unités statistiques, que l'on veut regrouper entre elles selon la ressemblance des valeurs qu'elles prennent. Les anglosaxons ont appelé cela "cluster analysis", ce qui se traduirait en français par "analyse des agglomérats" ou "analyse des conglomérats".Petite revue de vocabulaire :
 |
 |
| Un exemple de "treemap" | Illustration de la regression logistique |
De manière empirique, on considère que la CAH peut être appliquée tant que le nombre d'individus ne dépasse pas 220. Pourquoi 220 !? Je n'en sais rien, mais ce seuil consacré par l'usage est efficace...La séquence générale d'une classification de Johnson est la suivante :
 |
 |
| L'agglomération d'un cluster ascendant | Les différents points-individus appartiennent à un cluster plat (couleurs) |
Cette méthode peut servir aussi bien à regrouper des individus (lignes) dans un arbre de catégories empiriques, qu'à regrouper des variables (colonnes) entre elles. L'idée est de transposer la table d'analyse, les individus devenant variables et vice-versa. Ce mécanisme de transposition est typique de l'analyse de données à la française, et assez peu connue des "data miners"...L'intérêt de regrouper les variables est de pouvoir les manipuler plus facilement, surtout si elles se comptent par centaines ou milliers, comme en text-mining ou en analyse d'entrepôt de données. Cela permet également de mieux les comprendre, c'est-à-dire d'expliciter le rôle de chacune dans un scénario d'analyse. Dès que l'on est capable d'interpréter ce rôle, le choix des variables à sélectionner ou à manipuler est considérablement facilité...
Développements complémentaires
La méthode de Johnson, si elle peut être utilisée de manière visuelle et intuitive, n'a pas été dépourvue d'appareil théorique pour autant. Il a fallu déterminer la notion de distance, ce qui a été particulièrement délicat dans le cas d'un arbre, pour deux raisons :La lexicométrie
La lexicométrie en analyse de données ne concerne que l'approche "bag of words".Pour plus de précisions, voir la page consacrée à la lexicométrie.
Aspect développé par Benzécri : AFC appliquée sur la matrice lexicale, nuage de mots-clés et de textes.
L'échec patent de l'analyse de données
Une première approche : les difficultés du data miningUn problème de publication : les algorithmes de l'école française ont une valeur objective, mais ne sont ni connus, ni débattus, ni même codés en librairies logicielles.
Les connaissances finissent sur étagère...Tentative d'ouverture vers le Japon, mais même problème.
Marquage et démarquage des connaissances et des avancées techniques, comme en football. Existant ou original ? "Benchmarking" ou analyse comparative
Une affaire politique ? Le cas des Random Markov Fields, les algorithmes d'optimisation des plans quinquennaux, les métiers de la finance et de l'actuariat
Le film "Pi" : financiers et kabbalistes bavent sur un mathématicien.
Notes :
- [1] Cela n'a probablement rien à voir avec la science, mais il est amusant de constater qu'en Magie énochienne il existe une génération d'esprits qui traitent de l'entrelacement des choses de la nature...[2] Ce que n'hésitent pas à faire certains "data miners" professionnels et francophones, qui emploient alors un vocabulaire francisé pour présenter les outils et concepts à leurs clients, puis les pousser jusqu'au niveau de richesse des travaux américains. Dans la partie data mining, je présente un dictionnaire des termes français et anglais.[3] A ne surtout pas confondre avec les "AttributeWeight" du data mining, qui sont des poids sur les colonnes pour ordonnancer les variables, et non les rangées.[4] Un nombre scalaire, du latin "scala", échelle, gamme, est un nombre au sens où nous l'entendons tous les jours, c'est-à-dire une quantité d'argent ou toute autre mesure extensive. Des développements mathématiques du dix-neuvième siècle ont cherché à développer un nouveau rôle pour le nombre, en l'occurrence une valeur cartographique : Un nombre associé à un point permettrait de localiser ce point précisément sur une image. L'ordonnancement des nombres et des chiffres à la queue-leu-leu que nous connaissons devient alors un cas particulier de tels nombres. Les développements ont consisté surtout à vérifier d'une part s'il n'y avait pas redondance et lien avec la théorie des vecteurs, d'autre part ce que deviennent les concepts géométriques (droite, plan, figures diverses) et algébrique (addition, soustraction, multiplication) ainsi mélangés. Ainsi, certains de ces nombres complexes ont la vertu de faire tourner les points et les figures lorsqu'on les utilise dans une multiplication; c'est pourquoi ces nombres sont particulièrement utilisés en physique ondulatoire, toutes applications confondues. Pour plus de précisions, voir la page mathématiques[5] Conclusion : si votre "ex" vous offre un bouquet de roses rouges, accrochez-le à un moteur, mettez en route et parlez-lui d'analyse de données pendant ce temps. Effet garanti ! Prévoir une trousse de secours au cas où...[6] En tant que "data miner", même débutant, je trouve complètement aberrante la méthode utilisée. Il existe des dizaines d'autres algorithmes pour réduire, sélectionner et classer les données, autrement plus fiables et plus précis, surtout que le choix des catégories n'engage que l'opinion de celui qui choisit sa filière de calcul ! J'aurais personnellement utilisé une réduction type "carte de Kohonen" ou bien une "SVD" maximisant l'entropie entre les composantes, ce qui permet de filtrer des phénomènes qui, bien que sous-jacents, seraient parasites[7] Il s'agit en fait d'une optimisation lagrangienne, où l'on introduit un coefficient auxiliaire "lambda", qui se retrouve à jouer le rôle de valeur propre.[8] La visualisation "bulle" est une image (2 dimensions) où les points sont représentés par des disques de couleur (1 dimension) et de rayon variable (1 D).[9] Je me souviendrais toujours avoir lu dans un vieux numéro du journal "le Nouvel Observateur" la présentation d'une image en espace de valeurs appliquée à l'Analyse Factorielle des Correspondances. Le journal présentait un "décortiquage" de la gauche plurielle selon différents axes tradition/modernité, marxisme/libéralisme, niveau d'éducation, etc...Je pense que ce schéma explique assez bien ce qui se passe en France depuis quelques années...[10] Si, comme le proposait le professeur Benzécri, la segmentation devait être faite de manière automatique - notamment en équilibrant le nombre de branches et leur population sur des critères d'Inertie, alors on a de facto une classification descendante hiérarchique (CDH) ou cluster "top-down"
- [11] En anglais "contingency board"
- [12] J'ai une fois entendu le terme de "priorisation", "prioriser les projets"
Retour à l'accueil
Remonter d'un niveau