
|
accueil > Contenu > Yang > Anneau > Data Mining |
 Numéro d'enregistrement : 00041985 |
Ce site est protégé par droit d'auteur. En l'occurrence, ce certificat de droit d'auteur n'est pas une licence d'exploitation : Ce qui est protégé est l'archivage officiel du contenu des pages à une date précise. Ainsi l'antériorité d'une création pourra être prouvée, c'est-à-dire que toute idée nouvelle circulant sur Internet et qui serait ma création pourrait être reconnue comme telle grâce à ce dépôt légal... |
Sommaire
- Le Data-Mining, à quoi ça sert ?
-
Le panel de techniques
- Les techniques de visualisation
- La classification non-supervisée, ou "clustering"
- La classification supervisée, ou "learning"
- La transformation d'attributs, ou "dimension reduction"
- La sélection d'attributs, ou "feature selection"
- L'emploi des règles
- L'analyse de données temporelles, ou "time series analysis"
- Différences avec l'Analyse de Données
- Les techniques dérivées
- Les applications et les bénéfices
- Les obstacles
- Etude de cas concrets
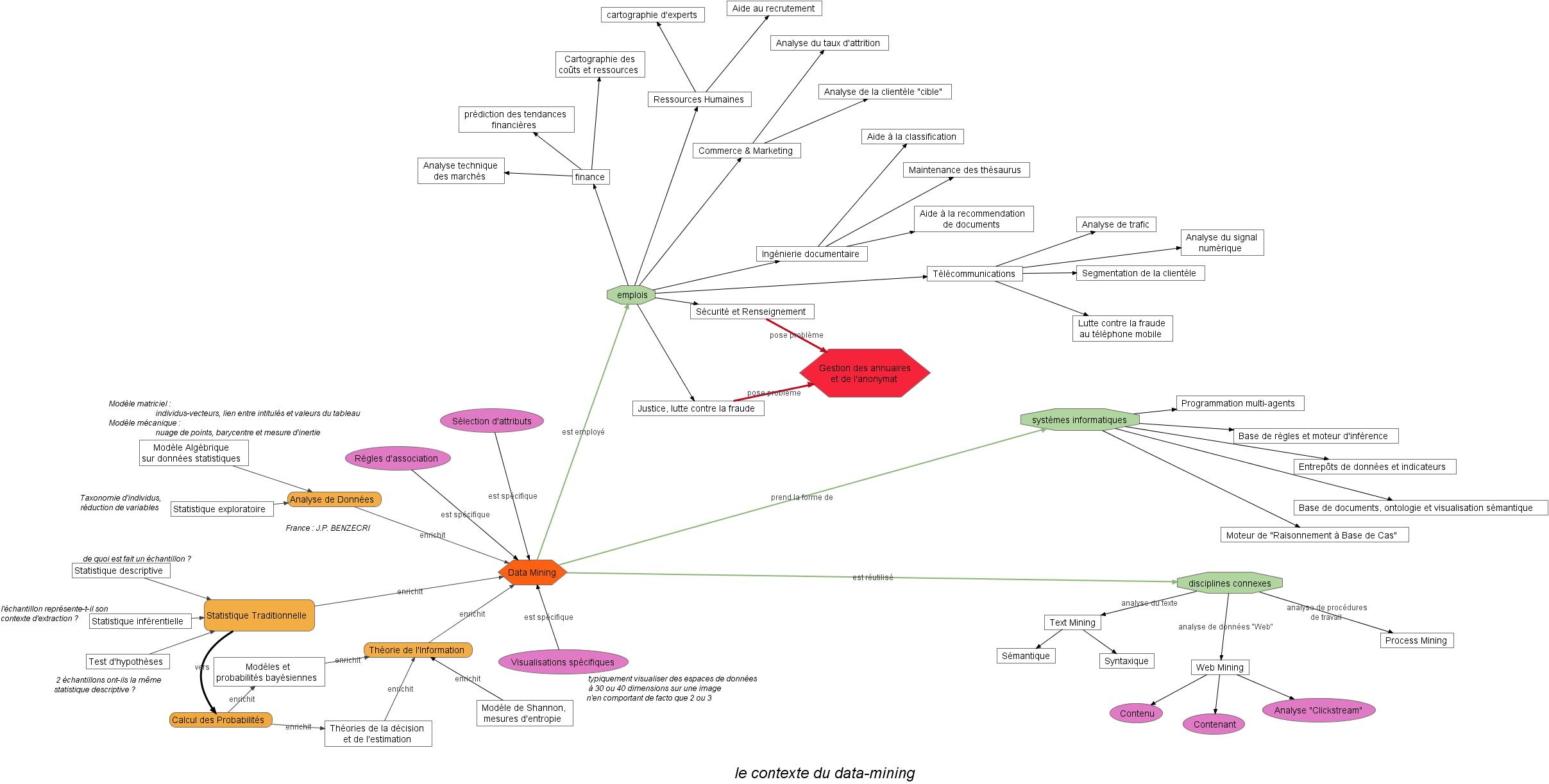
Le Data-Mining, à quoi ça sert ?
Tous les travaux, exemples et théories de cette page peuvent être vérifiés en utilisant le logiciel gratuit RapidMiner/Yale.Le Data Mining, ou "forage/fouille de données", est un terme forgé par le Massachusetts Institute of Technology vers les années 1980. L'idée principale est de valoriser la mémoire et les données d'une entreprise ou d'une entité en les explorant au moyen de techniques de mathématiques appliquées. Le MIT annonçait que cette technologie de l'information préparait la prochaine révolution du siècle...Au temps d'en juger !
On retrouvera certaines techniques du Data Mining en statistique "exploratoire", dès les années 1960, avec l'éminent professeur Benzécri J.P. de l'Université de Lyon. Toutefois, il semble que ses découvertes, fort en avance sur son époque, aient peu ou prou suscité l'intérêt du milieu industriel et des institutions. C'est donc avec surprise que le Data-Mining est une redite, fort enrichie depuis, de l'Analyse de Données du professeur Benzecri.
Ces techniques ont trouvé d'excellents clients dans la finance, le marketing, le suivi du client, etc...Le monde contemporain, avec sa logique financière redoutable, l'obsession de la concurrence, l'efficacité du marketing, en toute honnêteté doivent pratiquement tout autant au Data Mining qu'à l'Analyse de Données.
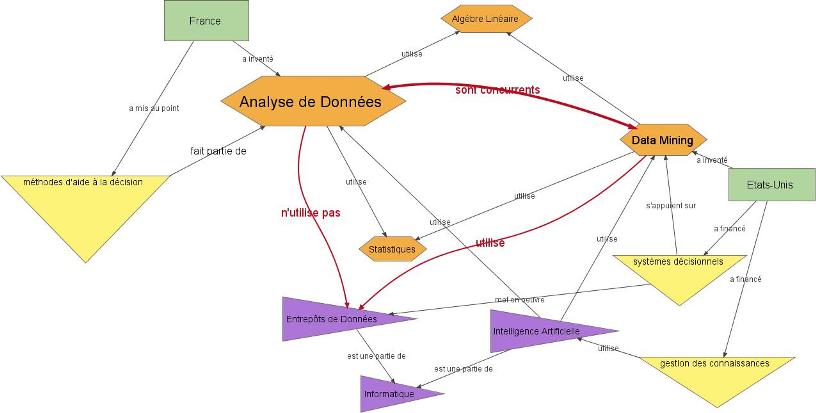
Pour expliquer ce qu'est le Data Mining, ses bases théoriques, ses applications, je vous propose une carte ci-dessous.
Une vue d'ensemble...
Cliquez sur l'imagette ci-dessous pour l'ouvrir dans une nouvelle fenêtreEn cliquant sur l'image qui apparaîtra, vous pourrez "zoomer" la carte, et vous y déplacer grâce aux "ascenceurs" de la fenêtre.
L'anecdote de Walmart
Je ne peux pas vous parler du Data Mining sans vous mentionner la tarte à la crème de la discipline, j'ai nommé l'anecdote de 'Walmart'...En 1960, les supermarchés américains Walmart avaient stocké tant d'archives de tickets de caisse qu'ils ne savaient plus quoi en faire. Ils firent appel à un data miner, qui ne tarda pas de découvrir la règle suivante : "Le samedi après-midi, lorsque X achète des couches pampers, X achète aussi des bières". alors ils se regardèrent tous les uns les autres, et l'un d'eux proposa l'explication suivante : En semaine, Madame fait les courses pour le bien être de la maisonnée. Mais le WE, c'est Monsieur qui s'y colle, aussi achète-t-il dans son caddie les couches du petit et les bières pour le match de foot du samedi soir !! Réaction du gérant : On va réorganiser les rayonnages, et mettre côte-à-côte les produits liés par une règle d'association. Il paraît que le chiffre d'affaires a décollé de 30% au bas mot...
C'est ainsi que votre magasin préféré va analyser vos achats, et à la caisse il vous sera remis un ruban imprimé d'offres d'achat n'ayant a priori aucun rapport avec votre caddie. Et pourtant...Achetez entre autres du pain, du fromage, du jambon : il y a fort à parier que le ruban vous mentionnera des offres sur les sandwiches !
Amusez-vous à imaginer et à extrapôler les associations qui ont servi à élaborer le ruban, parfois ce n'est franchement pas évident. C'est cela que l'on nomme la découverte de connaissances, une manière de brasser les données pour changer de point de vue.
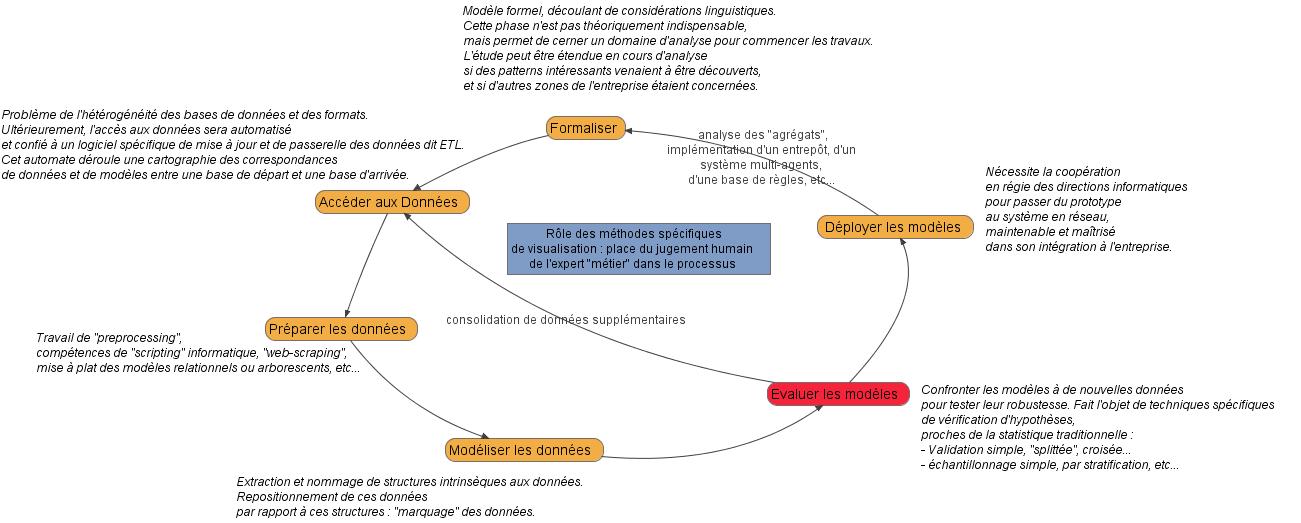
Le processus du Data Mining :
Le Data Mining est une démarche empirique. On doit donc à tout prix éviter d'avoir des a-priori ou des objectifs à tenir. C'est l'une des difficultés majeures de cette discipline, qui est alors délicate à spécifier dans un cahier des charges traditionnel.Généralement, on donne des spécifications initiales définissant un domaine d'analyse, et une problématique à résoudre. Toutefois, l'étude peut rapidement changer de cap en fonctions des résultats, car l'analyse même permet de définir les variables, les groupes de variables ou les modèles les plus importants, redéfinissant du même coup la vraie problématique.
Quelque soit la représentation d'un processus de travail en Data Mining, il est préférable de retenir que c'est :
- Une démarche définie à la carte, in vivo
- Un cycle d'apprentissage, où les résultats d'une phase spécifient les objectifs de la suivante.
- Une équipe triptyque, où l'analyste, l'expert métier et l'informaticien ne se séparent jamais.
Le panel de techniques
Le data mining doit être vu comme une boîte à outils, dans laquelle l'analyste ira piocher tout le long de l'analyse. Son savoir-faire réside donc essentiellement dans une combinatoire d'un catalogue de techniques, définie à la carte et validée par l'expertise visuelle des résultats.Les techniques de visualisation
Des travaux en Intelligence Artificielle ont montré qu'il n'existe que trois formes de représentation des connaissances :Le Data Mining n'échappant pas à la règle, on se servira de ces trois moyens dans les cas suivants et de manière non-exhaustive :
- L'arbre
- Cluster hiérarchique, Classificateur arborescent, taxonomie de variables
- Le graphe
- Classificateur par réseau bayésien, règle d'association
- Le tableau
- "scatter matrix", pratiquement toutes les autres visualisations
| Table d'analyse | Image de la table | Nom de la visualisation |
 |
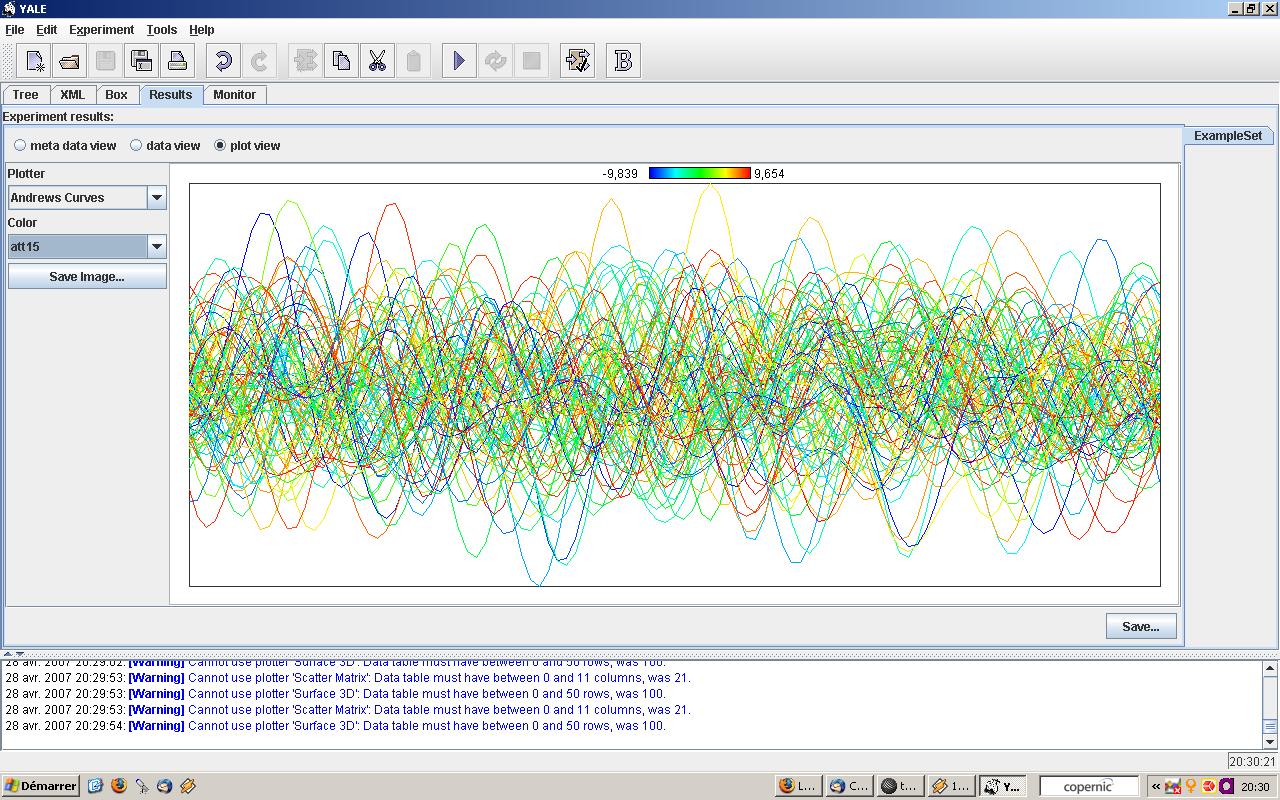 |
Andrew |
 |
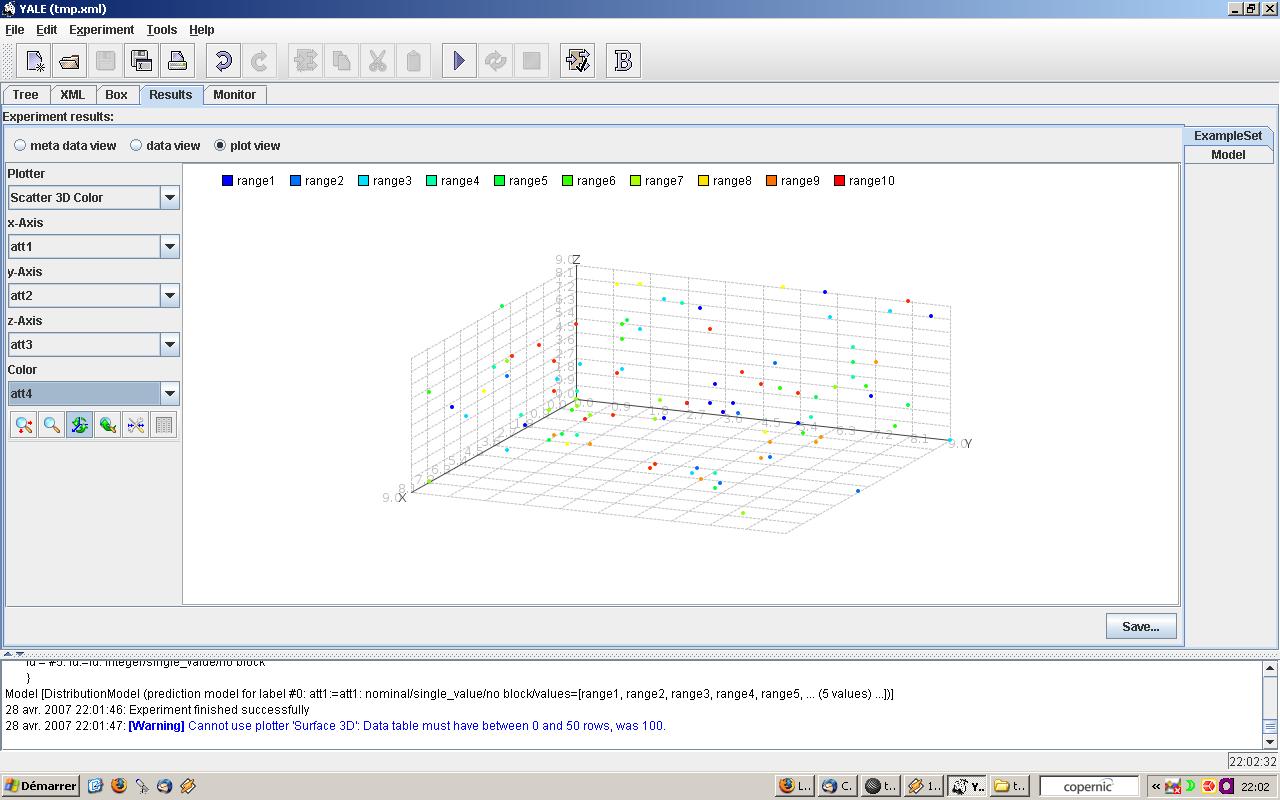 |
3D couleur |
 |
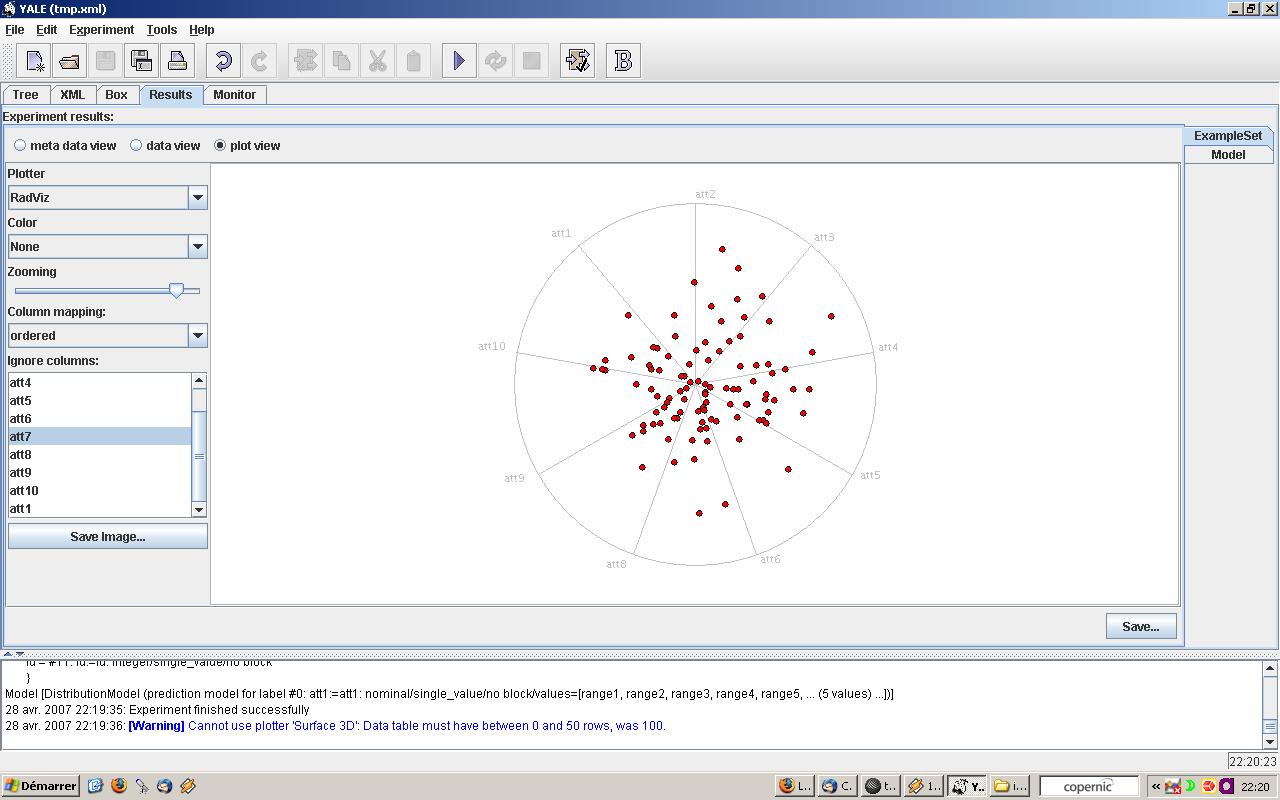 |
Radial |
 |
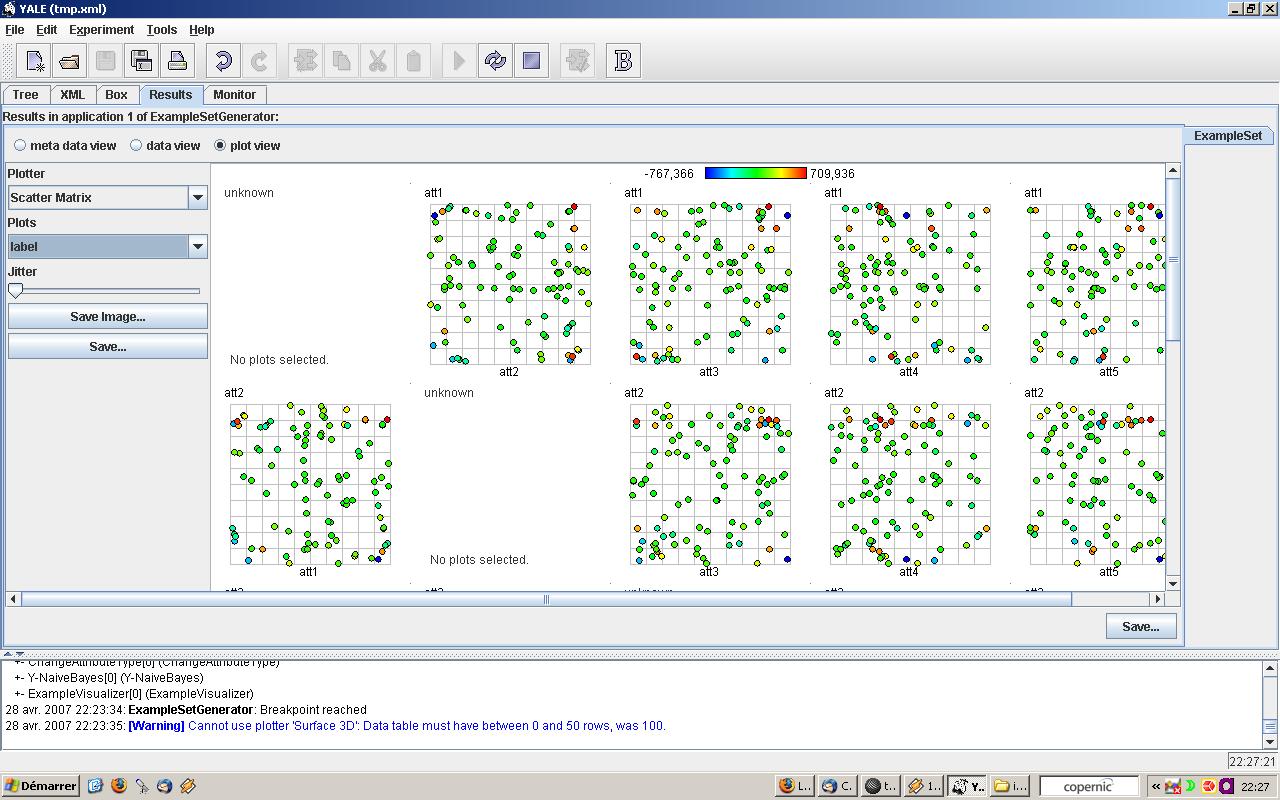 |
Scatter Matrix |
|
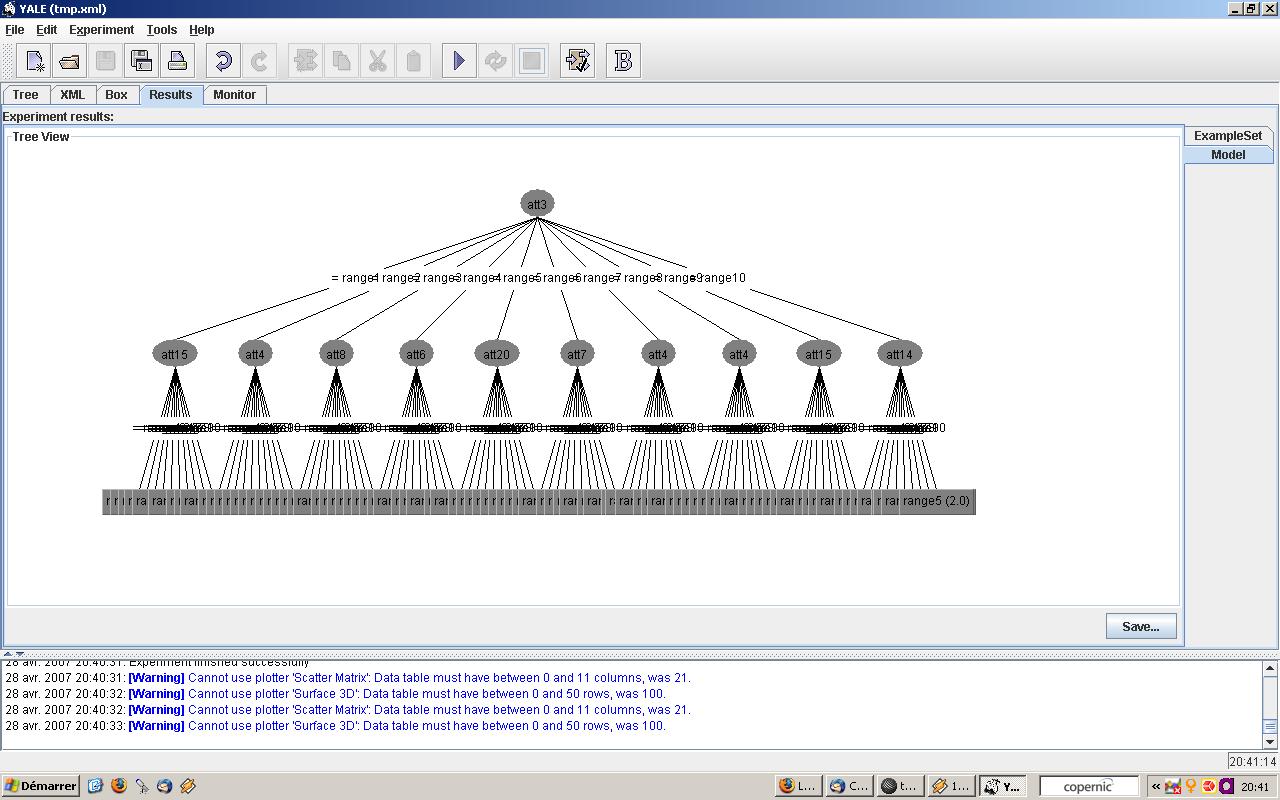 |
Arbre de décision |
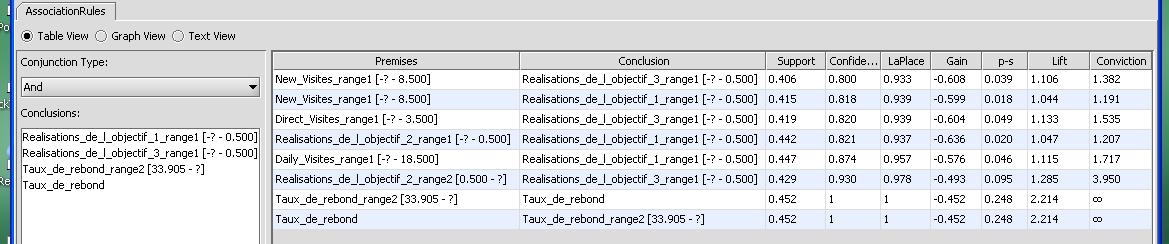 |
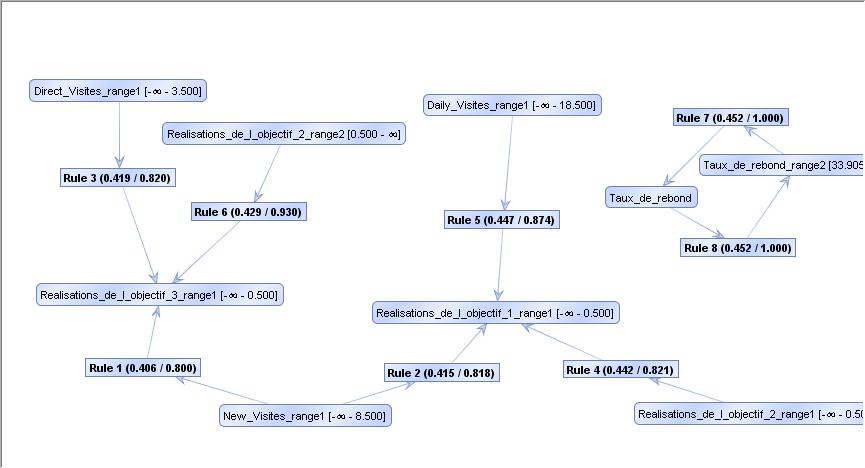 |
Règles d'association |
| Mierswa, Ingo and Wurst, Michael and Klinkenberg, Ralf and Scholz, Martin and Euler, Timm: YALE: Rapid Prototyping for Complex Data Mining Tasks, in Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD-06), 2006. | ||
L'un des autres problèmes cruciaux du Data Mining est de pouvoir visualiser des individus représentés par plus de 3 variables : à chaque ligne d'un tableau correspond un individu statistique, et chaque colonne désigne une variable de mesures. Alors une vue en trois dimensions suffit à représenter la dispersion et la répartition des individus. Pour un nombre de variables supérieur à 3, des visualisations complexes en 2 ou 3 dimensions introduisent une distorsion sur la valeur des données afin de pouvoir les visualiser. Il est donc nécessaire de posséder la connaissance de la transformation effectuée sur les variables pour pouvoir interpréter l'image des données, souvent de style psychédélique...!
Une référence intéressante sur l'exploration graphique des données.
La classification non-supervisée, ou "clustering"
Le principe est de disposer d'un ensemble d'individus, que l'on cherche à regrouper de manière "intelligente" sans a-priori. Existerait-il des groupements d'individus, intrinsèques aux valeurs que prennent les variables ?L'analyse des "clusters" ou "analyse des aggrégats" va ainsi produire un système de classement et de navigation dans les données, ex nihilo si j'ose dire. Ce système peut être soit une liste de catégorie, soit un arbre de catégories[7]. La technique la plus populaire est la classification ascendante hiérarchique, dont je parle en analyse de données. Toutefois, en pratique, on ne se sert que rarement d'un arbre de taxonomie complet, pour une raison liée à l'usage de cet arbre, un tantinet encombrant...L'idée est de ramener cet arbre à une liste, comme par exemple en ne prenant que les premières branches, si cela était suffisant...Les deux raisons pour cet "aplatissement" du dendogramme sont :
- L'utilisation de l'arbre comme système opérationnel de classification. Il faut qu'une telle taxonomie soit stable, indépendante des individus, ce qui se traduit par le choix d'une profondeur de l'arbre
- L'utilisation de l'arbre comme nouvelle variable expliquée de chaque individu, ce qui permet de poursuivre plus avant une fouille de données. On ne peut prendre en variable expliquée que des variables à liste de valeurs discrètes
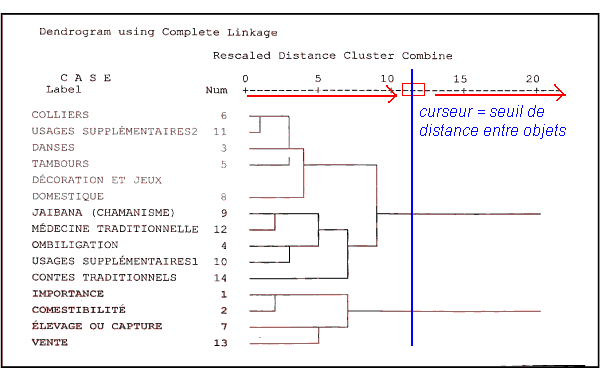 |
 |
| L'agglomération d'un cluster ascendant | Les différents points-individus appartiennent à un cluster plat (couleurs) |
- Pour un même ensemble initial de données, ces différentes méthodes ne donnent que très rarement les mêmes résultats. D'où l'intérêt de visualiser les clusters, de mesurer leur dispersion et d'essayer différentes méthodes...
- Le cluster hiérarchique descendant est très efficace pour un nombre d'individus inférieur à 200 environ.
- Au-delà, mieux vaut éclater le corpus par un flat cluster, et procéder à une analyse de chaque morceau séparément.
- Il est toujours très intéressant de disposer de mesures sur la forme des clusters obtenus, en particulier les "flat clusters". Cela permet de déterminer à 80% le type d'algorithme à utiliser et le nombre de clusters à imposer en début de calcul.
- d'une part révéler des connaissances implicites et donc admettre un nouveau moyen de classification de l'information,
- d'autre part elle révèle la structure interne d'une population de données et rend plus pertinente ses statistiques de description : on ne peut comparer que ce qui est comparable, justement dans chaque branche du cluster les individus sont réputés similaires...
- Quel type de distance choisir, en fonction de la nature des valeurs ?
- Quelle configuration de distance choisir, selon que l'on compare des individus, des groupes, ou un mélange des deux ?
- Quel type de cluster choisir ? Plat ou arborescent ?
- Quelle stratégie suivre pour obtenir le type précédent ? Aplatir un arbre, créer un arbre d'une liste par schéma descendant, ou utiliser directement la forme voulue ?
- Quel type de vérification utiliser ? statistiques descriptives des clusters, approches à base de densité ?
La classification supervisée, ou "learning"
Supposons maintenant que nous disposions :- d'une liste ou d'un arbre de catégories.
- d'un ensemble de documents/données à classer dans ces catégories
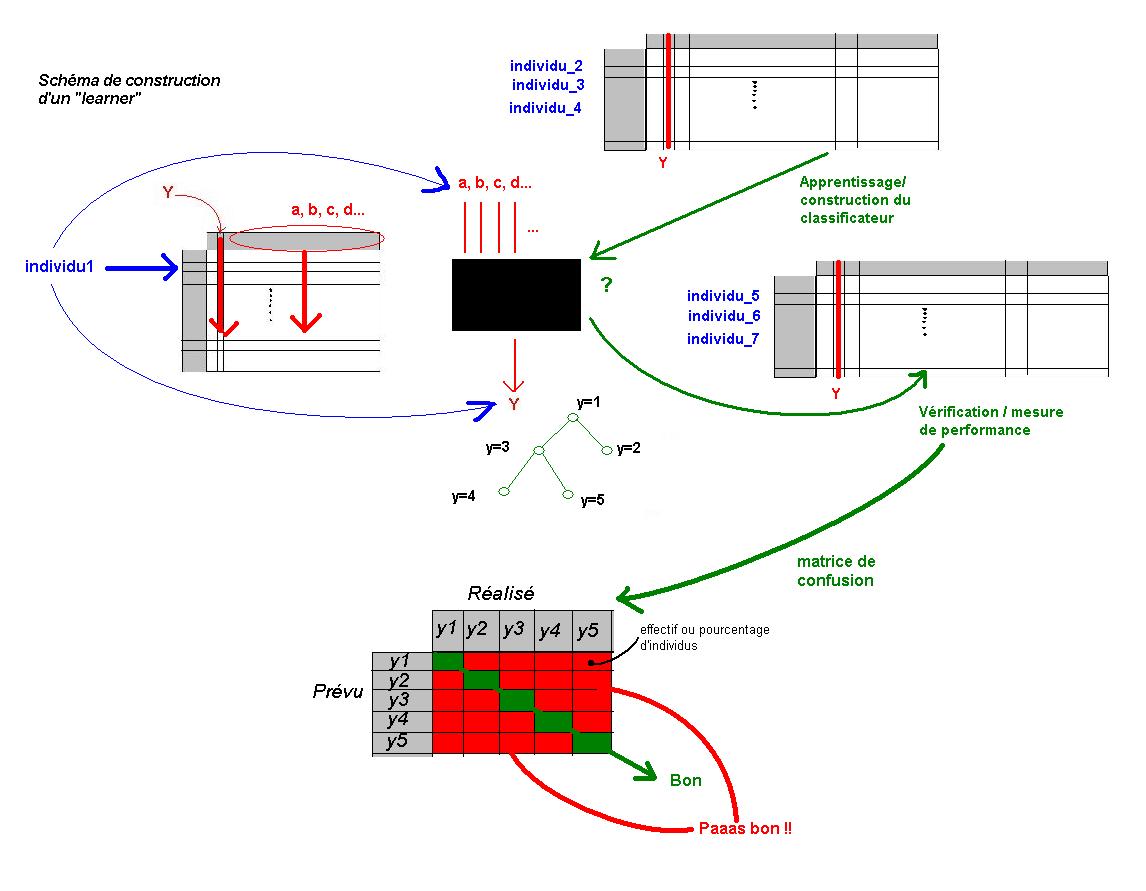
- Un pour régler le classificateur : le Train Set
- Un pour vérifier son efficacité : le Test Set
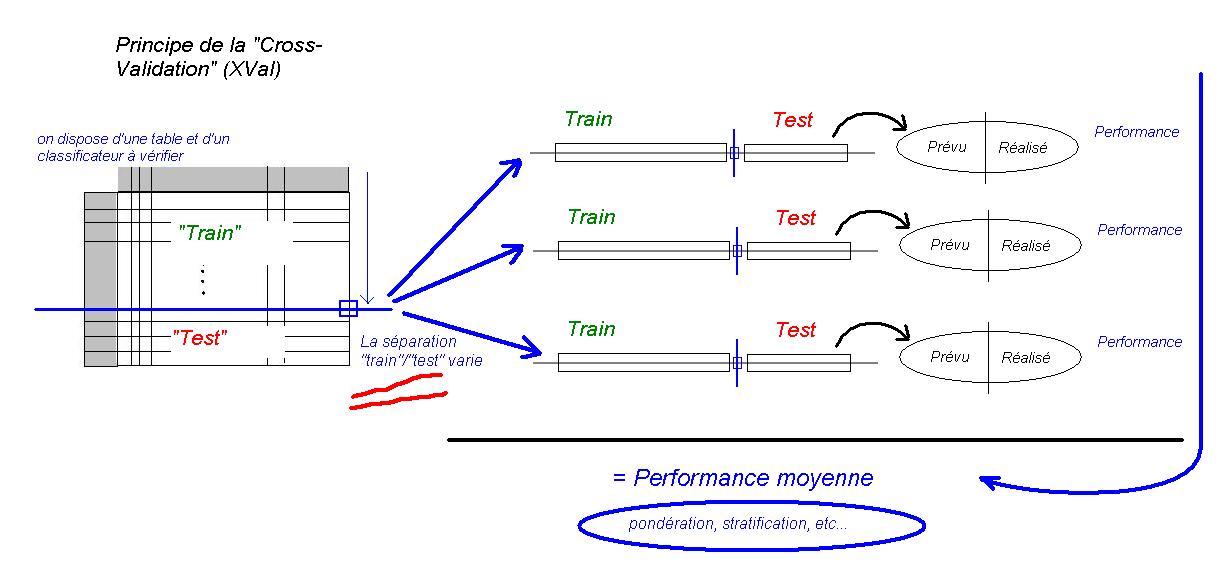
- On ne dispose souvent que d'un ensemble de données. Il faut les découper en deux lots
- Comment découper le corpus initial de manière à garantir que les deux sous-ensembles représentent la même statistique ?
- Peut-on effectuer plusieurs découpages différents sur lesquels effectuer plusieurs entraînements et plusieurs tests ?
- Comment synthétiser le résultat de ces différents tests ?
- Comment évaluer les performances d'un classificateur ?
En Data Mining, on utilise un opérateur informatique qui effectue l'entraînement et la vérification du "Learner" sur un corpus unique en effectuant plusieurs apprentissages et plusieurs vérifications. On parle de "vérification croisée" ou Cross-Validation.
L'emploi d'un classificateur dépend également du type de données que l'on veut manipuler : sont-ce des données numériques en entrée, ou des données qualitatives prenant un nombre limité de valeurs ?
Il existe ainsi un catalogue très riche de classificateurs, par ordre croissant de pouvoir de visualisation :
-
Régressions
- Régression linéaire
- Régression logistique
-
Fonctions et noyaux
- Machines à support vecteur
- Mesures de proximités et de ressemblance à des "délégués de classe" (!)
- Connexionnisme
- Réseaux bayésiens (très employés dans les antispams de messagerie)
- Réseaux de neurones
- Règles de logique
- formelle
- logique floue
- recherche d'exceptions
- table logique
- Arbres de décision
La transformation d'attributs, ou "dimension reduction"
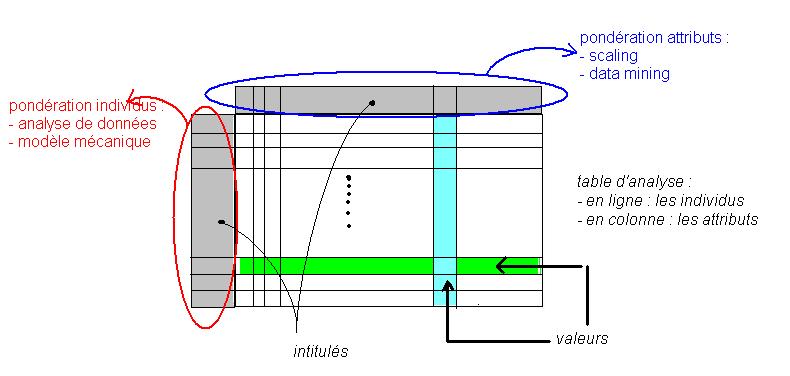
Manifestement, c'est une technique qui a été imaginée et introduite par l'analyse de données. Le modèle algébrique du professeur Benzécri permettait de faire le lien entre les intitulés et les valeurs de la table d'analyse :- Intitulés des rangées (identifiant des individus)
- Valeurs des rangées (description des individus selon l'âge, le poids, etc...)
- Intitulés des colonnes (nom des variables de mesure)
- Valeurs des colonnes (moyenne et dispersion des valeurs prises par les attributs, la pyramide des âges en est un exemple)
L'interprétation de ces nouvelles variables peut être particulièrement intéressante :
- Dans le cas du Text Mining, ces axes peuvent représenter des thématiques qui articulent le corpus de documents
- Dans le cas d'une enquête d'opinion, ils peuvent représenter des données sociologiques du genre "niveau d'éducation", calculé en fonction du niveau de diplôme et du type d'emploi...
- Dans le cas de données géographiques, ces axes peuvent représenter des zones thématiques, zones de la famine dans le monde, de la petite criminalité, du développement durable...
Il est donc toujours extrêmement intéressant de réduire la dimension d'une table d'analyse, en particulier après une sélection d'attributs. Cela permet d'augmenter la lisibilité d'une liste de résultats statistiques et de mieux cartographier la situation. En outre, la réduction de dimensions est toujours la meilleure opportunité pour introduire la connaissance du métier de l'expert qui interprète les axes.
La sélection d'attributs, ou "feature selection"
Plutôt que de réduire les dimensions, on va essayer de sélectionner les attributs les plus pertinents. Pour une population d'individus d'un pays, sont-ce l'âge, la taille, le niveau de diplôme, le nombre de frères et soeurs qui sont le plus important ? Par ailleurs, que fait-on des "ex-aequo" dans le classement de ces attributs ? Deux attributs pris ensemble ne sont-ils pas plus efficaces ensemble, et donc auraient un rang plus élevé que chacun d'eux seuls ?On peut donc effectuer une sélection d'attributs après les avoir rangés selon un classement, puis filtrés par un simple ou double seuil (fenêtre) sur ce classement. L'important est de générer le classement, que l'on appellera "pondération des attributs".
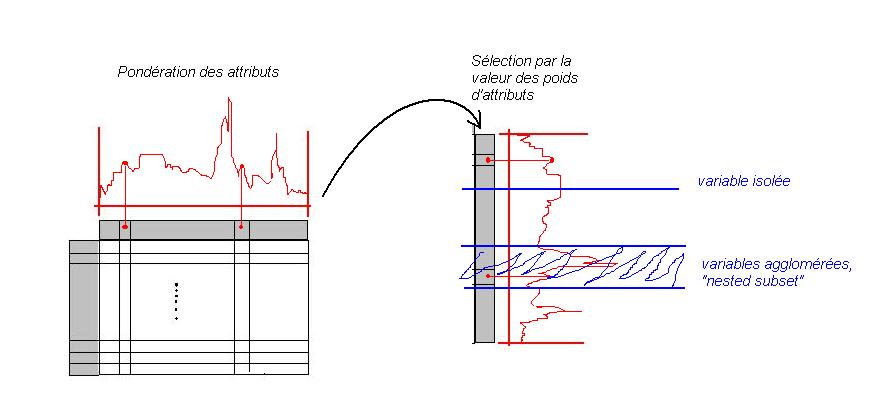
- La visualisation des attributs selon leur poids
- La pondération non-supervisée
- La pondération supervisée
Par ailleurs, la visualisation permet de porter un jugement sur les deux autres méthodes, d'évaluer tout à la fois le choix du type de pondération, ainsi que la valeur des seuils de filtrage.
La pondération non-supervisée, aussi appelée "approche filtering", consiste à comparer les attributs entre eux en fonction des valeurs qu'ils prennent pour chaque individu. Le test le plus simple est le critère de Pearson, qui est le calcul du coefficient de corrélation entre attributs. Le carré du coefficient vaut directement le poids de l'attribut, ce qui signifie que l'attribut de poids maximal porte autant d'information que tous les autres.
De manière générale, les approches "filtering" cherchent à mesurer l'indépendance, la corrélation ou l'information mutuelle entre attributs.
La pondération supervisée consiste à disposer d'un attribut de classification des individus, et d'évaluer le pouvoir décisionnel des autres attributs sur cette classification. Si je fais varier tous mes attributs de la même quantité, auront-ils le même impact sur les performances d'un classificateur ? Cette pondération est également particulièrement efficace et intéressante, car les attributs sont mieux discriminés, et de plus elle révèle la mécanique interne d'un classificateur, permettant là aussi d'introduire les connaissances de l'expert pour expliquer le poids des attributs dans la prise de décision.
Ainsi a-t-on coutume de dire qu'un réseau de neurones (un classificateur particulier), c'est bien, ça fonctionne mais on ne sait pas pourquoi...L'application d'une pondération supervisée permet de mettre en lumière de manière magistrale quels rôles jouent chacun des attributs dans la prise de décision. On parle "d'approche Wrapper".
Il reste une dernière phase dont nous avons parlé : une fois le classement généré, il s'agit de ne retenir que les attributs jugés intéressants. Un jeu de seuils peut faire l'affaire, toutefois il existe des approches plus complexes se rapprochant de la programmation génétique, où les attributs sont mis en concurrence sur leurs poids respectifs.
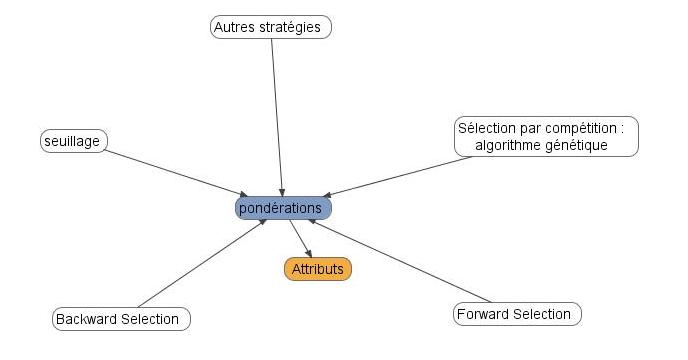
- Backward selection : C'est exactement le principe du maillon faible. Un automate de calcul prend l'intégralité des attributs, puis les élimine un-à-un selon des règles de progression spécifiées. A la fin de l'algorithme, le nombre d'attributs peut être divisé par 10; c'est l'approche que je préfère incontestablement en Text Mining.
- Forward selection : C'est exactement le principe de la constitution des équipes de football. A chaque tour de désignation, le capitaine de l'équipe va choisir le meilleur individu dans le groupe restant, augmentant ainsi l'effectif de son équipe.
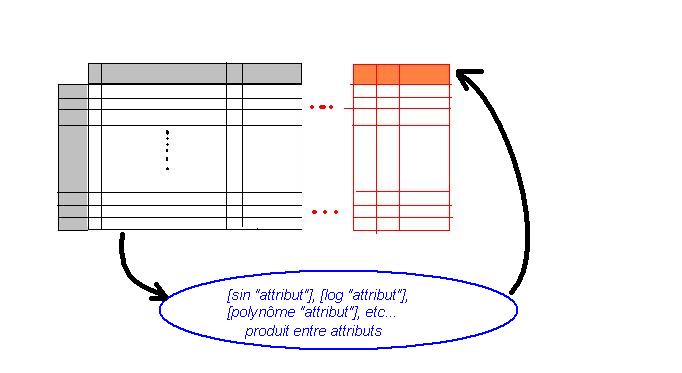
De manière générale, le succès d'une fouille de données repose à 80% sur cette phase de "Feature Selection" : Elle permet d'expliciter le plus de connaissances cachées dans les données, et simplifie considérablement les autres aspects de la fouille, en clustering ou en classification.
Une liste non-exhaustive de techniques de pondération d'attributs :
- Par la variance des valeurs d'un attribut
- Par le pourcentage d'inertie expliquée dans une ACP
- Par la comparaison des individus et de leur appartenance à un groupe particulier
- Par la corrélation des attributs entre eux
- Par le pouvoir décisionnel de chaque attribut dans un classificateur "Machine à Support Vecteur"
- Par l'entropie d'un attribut (répartition nombre d'individus / intervalles de valeurs prises par l'attribut)
L'emploi des règles
Historiquement, les règles d'association sont celles qui ont permis les premières analyses de panier. Si untel achète cela, qu'achète-t-il dans la foulée ? C'est le principe du site Amazon.fr, où une phrase du genre "les internautes qui ont acheté ce livre ont aussi acheté..." vous pousse à ressortir la carte bleue...Vous trouverez un mécanisme similaire sur le moteur de recherche Alexa, où un petit mouchard traceur relève votre fréquentation de site sans toutefois compromettre votre identité. La machine fait alors tourner un algorithme de règles d'association pour savoir ce que les internautes ont également consulté. Ce moteur est très pratique pour trouver des concurrents, ou trouver des produits similaires.
Une règle d'association ne mentionne aucun individu. Elle ne met en jeu que des relations entre variables qui se sont produites sur un nombre suffisant d'individus pour être généralisées. Elles sont accompagnées d'un indice de confiance lié à ce nombre d'individus "liés" par rapport au nombre total d'individus disponibles. Elles s'écrivent comme une déduction, avec une prémisse A et une conclusion B : A => B
Les règles d'association peuvent très bien être couplées entre elles, la conclusion d'une règle faisant partie de la prémisse d'une autre. Ainsi peut-on obtenir un réseau maillé de règles. L'important est de pouvoir distinguer les règles utiles, c'est la phase d'assession.
En classification supervisée
Certaines règles peuvent jouer un rôle particulier. En effet, si l'on dispose d'un attribut d'étiquetage des individus appartenant à un sous-groupe, on peut espérer trouver des règles d'association dont la conclusion porte sur cet attribut de sous-groupe. La règle prend alors la forme suivante :SI Attribut_X > 5 ET Attribut_Y > 3 ALORS individu_17 appartient à Groupe_3
La règle est alors de facto un classificateur. Il faudra probablement plusieurs règles de ce type pour former un classificateur complet, qui peut être un réseau de règles floues, une table de règles, un classificateur arborescent, etc...
Une analyse des règles peut donc être précédée d'une sélection d'attributs, ce qui aura l'avantage de :
- réduire la charge de calcul et rendre l'analyse abordable
- Repérer les groupes d'attributs susceptibles de former des supports de règles et permettre de choisir l'algorithme de règles approprié.
- Qualifier une famille de classificateurs non-linéaires, à base de graphes, d'arbres ou de règles
- Faire tourner un Wrapper afin de déterminer les attributs les plus fréquents dans les prémisses, et mettre en lumière des logiques de métier.
Un cas particulier : les règles d'association A priori
Les règles d'association fonctionnent en liant des attributs entre eux, et non des individus. Elles analysent l'occurrence de valeurs plus ou moins fréquentes selon le nombre d'individus qui présentent ces valeurs pour des attributs donnés.Encore faut-il trouver les bons attributs. Pour cela, il faut explorer une combinatoire d'attributs, ce qui peut rapidement devenir infernal en termes de charge de calcul. Le principe des règles d'association est toujours le même, seul change l'algorithme qui permet de gérer au mieux cette combinatoire. Supposons que nous ayons trois attributs à explorer. La règle la plus simple qui pourrait être trouvée est celle qui relierait un seul attribut à un seul autre. Nous aurions donc une combinatoire "deux à deux parmi trois", ce qui fait trois tables de deux colonnes chacune.
Supposons maintenant que nous ayons quatre attributs, soit une combinatoire "deux à deux parmi quatre", ce qui fait six tables à deux colonnes chacunes. Et ainsi de suite...
Dans cette optique, l'algorithme A priori va d'abord chercher les colonnes susceptibles de contenir une règle (on parle de support de la règle) puis ne chercher les règles que sur ce support. D'où le nom de l'algorithme. La recherche de support s'appuie sur le principe suivant :
- On recherche les groupements de valeurs les plus fréquents (histogramme des valeurs d'un attribut)
- Tout sous-groupement d'un groupement fréquent doit aussi être fréquent, sinon on élimine le "groupement fréquent"
- On ne doit pas tester un quelconque agglomérat de groupements non-fréquents
Les groupements qui remplissent ces conditions pour des seuils données de fréquence sont déclarés "supports de règles". Les règles sont alors recherchées dans ces supports.
L'analyse de données temporelles, ou "time series analysis"
Le modèle de données chronologiques
Séries temporelles :- Interprétation du modèle "1 attribut = 1 échantillon", modèle multivarié
-
Le rôle du temps : stochastique contre économétrique
- Stochastique : retour à la table d'analyse traditionnelle
- Econométrique : le présent dépend du passé, et le futur aussi. C'est du "traitement de signal économique"
- Ne pas mélanger les deux : Le stochastique est complètement libre du temps; l'idée est une collection d'objets, tous différents mais issus d'un même phénomène
- Ne pas mélanger série prévisionnelle et série de données avérées
La prévision : une hybridation de sous-modèles
-
Prévision, prédiction et filtrage :
- Décomposer la prévision en sous-prévisions
- Un sous-modèle par sous-prévision
- Le modèle prévisionnel est un assemblage de sous-modèles
-
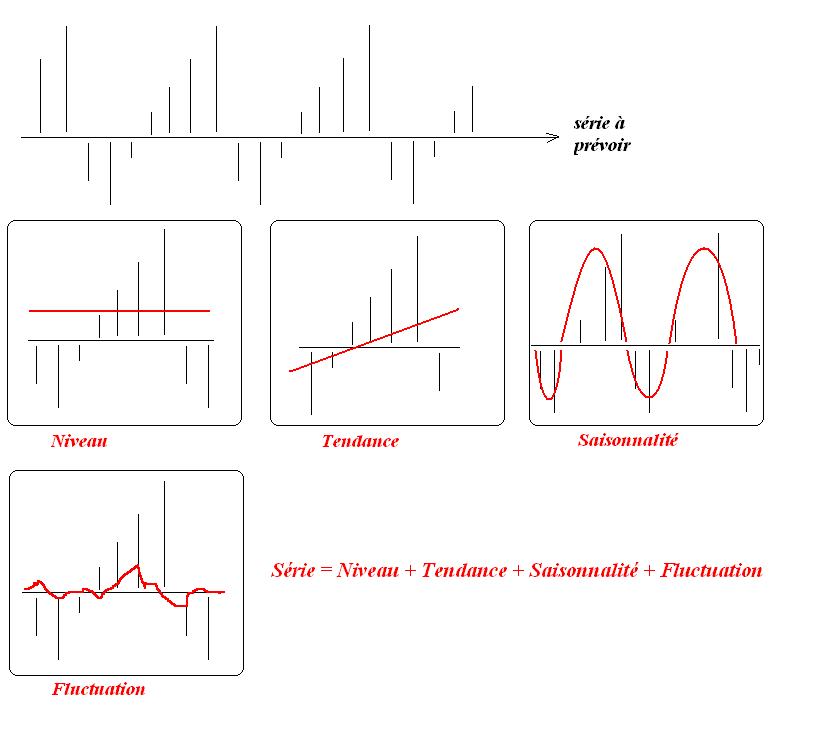
Traditionnellement : Analyse des 4 tendances {niveau, tendance, saisonnalité, fluctuation}
- Niveau
- Tendance
- Saisonnalité
- Variations
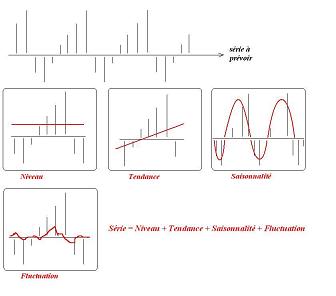
Généralisation du principe de décomposition de la prévision :
- Analogie avec les développements limités
- Analogie avec l'analyse harmonique
- Analogie avec l'analyse "petits signaux" dans la théorie des transistors
- Une composante de rang supérieur est plus "agitée", mais de plus faible amplitude que la composante de rang précédent
- Extension : l'analyse multi-résolution (ondelettes, courbelettes, voir plus bas "sciences de la Terre")
-
Extrait du site du Centre de Physique Théorique de Marseille - Notion de dérive, apprentissage à la volée

Les filtrages temporels
-
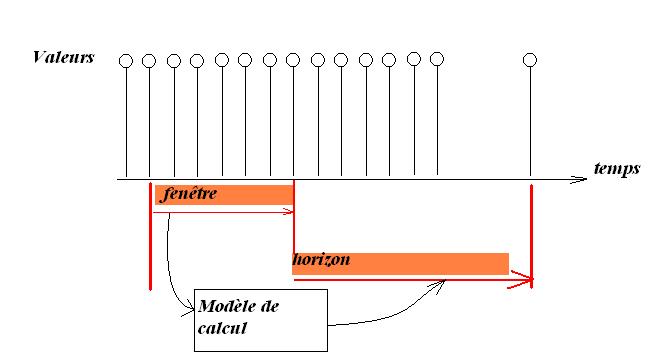
Notion de fenêtre, d'horizon. Problème : détermination de la taille de la fenêtre pour un horizon et une composante de prévision donnés
Indicateurs de taille de fenêtre, autocorrélations, intercorrélations, noyaux de calcul, problématique de la pondération des fenêtres glissantes de FFT en TNS 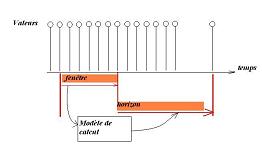
-
Filtre de Kalman, lissage exponentiel
- Filtre de Kalman, présentation, schéma
- Lissages exponentiels : principe (tenir compte des prévisions passées dans le calcul des prévisions futures, choix dépend de la composante à prédire), Brown, Holt, Holt-Winters
- Entrées "exogènes", entrée de commande "B.u" dans Kalman, modèles "X" dans Box-Jenkins (ARX, ARMAX). Emploi des modèles à entrées exogènes typiquement en Robotique. Réponse impulsionnelle, réponse percusionnelle; réponse à un échelon pour estimer la réponse impulsionnelle, rôle d'un échelon dans la causalité d'un signal, transformée de Hilbert en fréquence, transformée de Hilbert en temps (filtre de quadrature pour voies I, Q)
-
TNS contre datamining : méthode de Box-Jenkins, dualité RII/RIF
- En TNS, théorie des filtres.
- Présentation : coeffs de combinaison linéaire, graphes de fluence sur DSP.
- Comportement fréquentiel : Gabarits de fréquence, passe-bas, passe-haut, passe-bande, coupe bande, entailleur, détecteur de pics
- Galerie de gabarits ici
- Comportement temporel, réponse impulsionnelle, corrélation/convolution (FFT à la volée), notion de masque (traitement d'images)
- Deux types de filtres (graphes de fluence) : RII et RIF. Puissance de calcul, stabilité et convergence, impacts sur la phase et l'amplitude. Schéma
- En datamining, méthode de Box-Jenkins :
- Deux types de séries prévisionnelles : AR (AutoRégressif, en fait intégration d'un lissage exponentiel) et MA (Mobile Average, moyenne mobile donc pas de lissage exponentiel).
- Double schéma ici
- Détection du type par les autocorrélations totale et partielle. Dualité des deux types
- Box-Jenkins : Toute série prévisionnelle est une composition des deux types. Composition des modèles : AR, MA, ARMA, ARMAMA, ARARMA selon le nombre de composantes à lisser (Holt-Winters, etc...)
- Parallélisme fondamental :
- AutoRégressif = Filtre à Réponse Impulsionnelle Infinie,
- Moyenne Mobile = Filtre à Réponse Impulsionnelle Finie
- En TNS, théorie des filtres.
Applications des séries temporelles
Partout où il y a un risque, il y a besoin d'estimation prédictive. Autant dire qu'une telle culture mathématique est indissociable des leçons politiques et morales du genre "prenez des risques pour devenir riche..."Emploi des séries temporelles dans les sciences de la Terre :
- Sismographie : ondelettes, sismelettes. Derniers séismes : Pérou, Sichuan
- Météorologie
- géographie, geoprofiling, geodatamining, trajectographie, analyse multirésolution "sur la sphère"
- Analyse des risques, assurances et banques
- Modèles a priori, hypothèses statistiques et optimisation paramétrique
- Modèles séquentiels, scénarios, prospective
AnalyticBridge.
Différences avec l'Analyse de Données
- Soit en les numérotant "à la queue-leu-leu"
- Soit en exprimant leur importance relative par un graphe d'ordonnancement, où chaque lien représente une relation de subordination, une préférence d'une variable sur l'autre.
Dès les années 50-60, le professeur Benzécri découvrit ces techniques et les ramena en France pour construire son modèle double d'analyse de données, où un certain nombre de techniques sont communes au data mining dont :
- Réduction de dimensions (ACP et AFC)
- "cluster" ascendant (CAH)
- "cluster" plat (K-means/nuées dynamiques)
-
analyse discriminante
- à but descriptif : "feature weighting"
- à but décisionnel : "learners"
C'est du data mining que viendra la pomme de discorde, puisque les théories probabilistes esquissées en analyse discriminante, mettant en avant les notions d'apprentissage et d'entropie sont systématiquement utilisées pour rendre les algorithmes plus performants. Et ça fonctionne !!
- "Le data mining, c'est pas de la statistique !!"
- "Mais nous n'avons jamais dit que cela en était..."
Concernant l'analyse des proximités, l'idée est l'inverse du "multidimensional scaling" : On part d'un graphe d'ordonnancement de différents individus entre eux, l'idée est de trouver et d'estimer un jeu d'attributs sur lequel tous les individus seraient mesurables, et qui transformerait ainsi le graphe en table d'analyse.
Les techniques dérivées
L'idée est de ramener une donnée, un lot de données à la structure d'une table d'analyse. Lorsque les données sont stockées en mémoire, elles peuvent l'être selon trois théories :- La liste : c'est le format de la table d'analyse. Le plus simple à lire, mais de loin le plus volumineux. Il faut pour cela un entrepôt de données
- L'arbre : c'est le mode de stockage des données linguistiques et de programmation, entre autres. C'est le cas d'XML, traité en linguistique formelle. Moins volumineux que le précédent, il ne rend pas compte de toutes les informations, notamment les liens transverses.
- Le graphe de la base de données relationnelle. C'est le format le plus compact, car il exprime directement les liens entre les entités sociales qui s'échangent des informations au sein d'un réseau. Chaque entité sociale est représentée par sa propre table, avec les informations qui lui sont spécifiques, et un mécanisme de repérage par référencement des données permet de relier les données d'une table à une autre table.
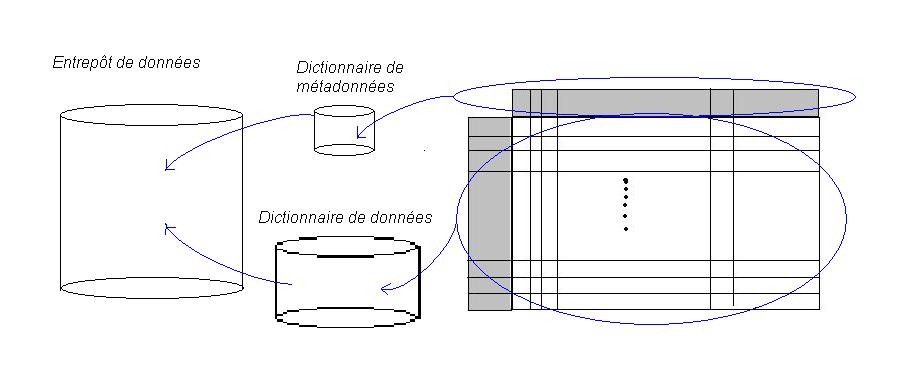
|
|
Cela nécessite donc un prétraitement collectif des données, de l'ordre de l'informatique de "scriptage"; en outre, si les données ne sont pas structurées, comme par exemple les bases de données documentaires, les textes, les paroles, le contenu des films, alors il faudra un prétraitement supplémentaire qui implique des connaissances en linguistique, en ingénierie du son (reconnaissance vocale), etc., de manière à les ramener à l'une des trois structures, puis à une table d'analyse.
Le Text Mining
Le Text Mining ou lexicométrie, est le principe de prétraiter du texte pour le ramener à une représentation sous forme de table d'analyse. Autant l'école française que l'école américaine travaillèrent sur le sujet, et proposèrent une première représentation sous forme de matrice lexicale. C'est l'approche bag of words, en français "sac de mots".Le Web Mining
Le Web Mining consiste à prétraiter des pages Web pour en extraire les données pertinentes. Ces pages Web peuvent se trouver sur Internet (cas de la veille) ou dans un Intranet (gestion des connaissances).Le sujet est plus délicat que le simple text mining, car pour des raisons de mise en forme, il faut extraire l'information utile au bon endroit dans la page : On parle de Webscraping. Une application typique du Webscraping est de veiller les bases de données de publication (scientifique, logistique, etc...), qui sont des bases documentaires dotées d'un catalogue de notices. Ce sont les notices, dont le format est le même mais le contenu différent, que l'on va considérer chacune comme un individu de la table d'analyse. Chaque notice est dotée d'une date, ce qui permet une analyse par série temporelle : suivre l'évolution des publications peut permettre de dégager des tendances et des associations intéressantes. Cette technique rejoint la problématique générale des formulaires.
En outre, le format des pages Web peut poser problème, en particulier pour les pages dynamiques comme celles écrites en PHP. Les pages dynamiques sont des fichiers qui contiennent des directives pour que le serveur du site consulté calcule le code HTML à envoyer sur le navigateur de l'internaute. Pourquoi une telle complexité ? Parce que le contenu d'une page Web peut très bien être différent d'une journée sur l'autre, et dépendre d'un contexte extérieur à la page. Ainsi, un forum ou un blog actif verront des questions et des commentaires s'ajouter dans le temps, ou bien une page Web peut afficher un compteur de visite ou l'heure, ce qui en toute logique est différent à chaque visite.
Ce genre de langage ouvre de grandes perspectives en matière d'édition de contenus, mais est un vrai casse-tête, une zone aveugle autant pour les moteurs de recherche que pour les pauvres data miners !
Enfin, l'analyse des pages Web consiste à analyser le contenu d'une page mais aussi les relations d'hyperliens qui sont la plus-value du Web. Il y a en fait trois types d'analyse sur les pages Web, que je traite dans les paragraphes suivants.
Le Web Pattern Mining
Le Web Pattern Mining ou analyse des liens entre pages Web a pour objet de valoriser l'information de lien entre les pages. Naturellement, chaque page peut être alors considérée comme le noeud d'un graphe. Dans le cas de pages Internet, le graphe est appelé Web Graph, et sa structure est particulièrement instructive sur la manière dont on doit référencer les pages pour plus de visibilité, et comment les retrouver. Il s'agit d'une véritable cartographie du Web. On trouvera des études très intéressantes sur le Web Graph ici. A savoir que l'Internet a une structure de papillon...Dans l'analyse d'un Intranet, cette partie est particulièrement importante car elle permettra entre autres de mettre en place une véritable cartographie des connaissances, c'est-à-dire :
- "où sont les experts et en quelle discipline ?"
- "comment circulent les connaissances et sur quels thèmes et critères ?"
Le Web Content Mining
L'analyse du contenu des pages Web s'appelle le "Web content mining". Cette méthode est naturellement à rapprocher du Text Mining. Toutefois, une exploitation croisée de la structure et du contenu des pages peut aboutir à une analyse plus fine des concepts importants dans le contenu, ou à l'inverse obtenir une cartographie plus précise des pages web entre elles.Personnellement, je me sers du Web mining avec YALE de manière à indexer mes propres pages de ce site, en intégrant les sous-pages liées.
L'analyse "clickstream"
L'analyse "clickstream" suppose de disposer d'une sonde logicielle sur chaque page Web, ce qui en pratique n'est possible que sur un Intranet ou un site spécifique. Chaque "clic" de souris est enregistré dans un fichier de chronologie, avec des attributs comme "date de clic", "nature du clic (droit/gauche)", "durée d'enfoncement du clic", "IP connectée", "URL de la page" et "URL pointée". Chaque individu de la table d'analyse est un clic, et l'on cherchera à détecter des tendances à travers la série temporelle ainsi constituée.Les résultats peuvent servir en analyse de trafic, mais aussi permettent d'évaluer l'ergonomie d'un site. On a ainsi coutume de dire que la durée entre deux clics est liée de manière croissante à l'intérêt porté à une page...Même si c'est un peu simpliste, ça peut être utile...
Un produit intéressant d'analyse clickstream couplé à un système "Business Intelligence" dont je me sers depuis peu pour ce site : Google analytics. Vous ouvrez un compte de contact (Gmail n'est pas nécessaire) chez Google, puis :
- Vous ouvrez un compte "analytics"
- Vous posez une sonde logicielle sur chacune de vos pages web, y compris les cadres
- Vous effectuez une vérification depuis le compte "analytics"
- Vous cliquez sur "afficher les rapports"
Le Process Mining
Le principe de récupérer des fichiers d'historique, des archives, des documents et de cartographier autant leur contenu que le contenant (catalogue) s'applique depuis quelques années aux processus industriels.Jusqu'ici, les industriels avaient mis en place des référentiels qualité pour donner un gage de transparence, de confiance et de maîtrise des coûts et délais dans une chaîne de fabrication. L'idée est que ce qui est écrit devait correspondre à ce qui est pratiqué et vice versa. On pouvait donc le cas échéant :
- "Recaler" les pratiques sur le référentiel documentaire
- Recaler le référentiel documentaire à partir des pratiques
La représentation de base en process mining n'est pas à ma connaissance la table d'analyse, mais le graphe de Petri. Je vous renvoie pour plus de précisions à l'adresse suivante.
Les applications et les bénéfices
Généralement, une démarche de data mining au sens large est déployée dans deux projets types :- Les systèmes d'aide à la décision
- Les systèmes de gestion des connaissances
Chaque modèle issu du data mining, pris séparément ou en conjonction avec d'autres modèles, peut justifier la construction d'une base de données spécifique en aval de l'entrepôt, permettant de visualiser l'évolution d'un indice ou la cartographie en axes principaux des données d'entrée. On parle de base OLAP pour "Online Analytical Processing". Un tel dispositif permet :
- aux décideurs de piloter une activité, car le tableau de visualisation permet de comparer le prévu au réalisé en s'appuyant sur des mesures objectives et synthétiques.
- aux traitants et analystes d'être plus à l'aise dans leur travail, car ils comprennent mieux ce qui se passe et ce qu'il faut faire, et bénéficient également du rangement efficace des données.
L'autre application majeure du data mining, plus dans sa dimension "text/web mining", concerne la gestion des connaissances. L'idée est que les connaissances circulent dans l'entreprise sous forme écrite ou orale, pas toujours sous forme visible; il faut autant que possible les "capturer" dans une base de données spécifique pour pouvoir les restituer à ceux qui en auront besoin. C'est le paradoxe : "A détient une information, B a besoin de cette information, A ne sait pas que B en a besoin, B ne sait pas que A la détient". Généralement, une telle démarche s'effectue en deux temps :
- La gestion collaborative de contenus
- La gestion des métadonnées, ou cartographie de l'information
Les systèmes les plus avancés d'aide à la décision ou de gestion des connaissances couplent ces deux aspects :
- Ils sont capables de faire des prédictions sur un horizon de temps (classification supervisée sur une série temporelle). C'est Madame Irma à la maison !!
- Ils sont capables d'expertiser une situation : Le système décisionnel explicite une situation, la modélise par ses indicateurs, tandis que le système de gestion des connaissances la qualifie, la nomme et effectue une comparaison avec des situations passées analogues en restituant les connaissances acquises alors, notamment la marche à suivre
En fait, dès lors que l'on possède des données qui peuvent être représentées sous forme d'individus repérés par des valeurs sur des variables, on peut appliquer les techniques de data mining et d'analyse de données. J'envisage une application curieuse et originale à ce sujet, notamment pour mes études ésotériques. Le système symbolique énochien est composé de tablettes abstruses et d'un langage aux allures de cryptage; l'inventeur du personnage de James Bond, Ian Fleming, avait même proposé l'emploi de ce système pour le codage des transmissions pendant la Seconde Guerre Mondiale du temps où il faisait partie des services secrets anglais. Mon idée est que chaque tablette est une population de lettres caractérisées chacune par deux variables de position et quelques variables supplémentaires comme "valeur de la lettre" et "chiffre de chemin". J'ai commencé à sortir quelques résultats, que j'envisage de publier un de ces quatre sur le site.
Les obstacles
"Je n'aime pas trop quand chaque chose est rangée dans une petite case informatique", "ne raconte pas de bêtises, on a besoin d'experts pour ce métier, pas de statisticiens"Voici quelques unes des réflexions auxquelles j'ai eu droit, comme d'autres certainement avant moi, à l'encontre d'une démarche de data mining. Les spécialistes du sujet sont très clairs sur ce point : sans volonté forte du plus haut niveau de la hiérarchie, aucune chance de faire aboutir un tel projet...
Ainsi un certain nombre de difficultés émaille la marche vers de tels systèmes. J'en ai listé quelques uns ci-dessous, à prendre en compte pour préparer "la bascule".
La polémique entre statisticiens et "data miners"
J'avais entendu parler, de la bouche d'un data miner professionnel, d'une polémique entre data miners américains et statisticiens français. Bien que cela soit uniquement une information orale, que je n'ai eu qu'une seule fois, cela m'avait tellement intrigué que j'ai cherché à comprendre pourquoi et comment.Je me suis intéressé à l'histoire de cette matière version "française" et version "américaine". Je constatais que la petite communauté scientifique cosmopolite n'avait pas de raisons d'avoir une polémique, comme si en physique ou en médecine on eu dit qu'il y a la technologie française et la technologie américaine et qu'elles seraient incompatibles. Je n'ai retrouvé de telles scissions que pour les sciences humaines.
J'en parlais à des collègues français, et cela commençait par un dialogue du genre :
- Tu sais, le data mining, c'est nouveau, ça va changer ceci celaEtrange paradoxe...
- Ah bon, et tu fais quoi avec ?
- réduction, classification, etc...
- Mais c'est connu depuis trente ou quarante ans en France !!
- Et comment cela se fait que rien n'est en place ?
- Parce que cela n'est pas connu, et que cela n'intéresse personne
Puis je découvris sur Internet un document sur lequel je n'arrive pas à remettre la main, un tableau particulièrement intéressant qui mettait en lumière la différence de conception de la connaissance chez les anglosaxons et chez les latins (français bille en tête). En effet, le data mining est utilisé dans les projets cités plus hauts sous le nom de "découverte de connaissances dans les bases de données"[1]. Le document avait la même teneur que cet article sur Wikipédia, et expliquait que pour les français, une connaissance devait pouvoir être vérifiable, démontrable, tandis que pour les anglosaxons elle devait être utile et visualisable.
Lorsque j'ai commencé à pratiquer le data mining, j'ai pu constater que mes interlocuteurs anglosaxons m'enjoignaient d'essayer, de pratiquer tandis que mes interlocuteurs français me faisaient remarquer que ce genre de statistiques ne pouvait pas être appréhendé n'importe comment, qu'il fallait avoir des bases théoriques solides.
De toutes ces observations, j'en tirais la conclusion suivante :
Il y a une différence fondamentale de culture et de valeurs entre les latins et les anglosaxons à prendre en compte dans un projet où l'on voudrait inclure du KDD.Pour un français, plus un algorithme est complexe, sophistiqué, moins il aura tendance à avoir d'applications pratiques car il sera soumis à plus de contrôle intellectuel par les experts. Son emploi sera restreint à un cadre extrêmement limité, où le risque supposé d'erreur de choix sera réduit au strict minimum. Ce faisant, il est impossible d'envisager pour un latin que le data mining soit une boîte à outils où l'on essaie les différents algorithmes jusqu'à en sortir quelque chose d'utile, inconnu et explicable.
Un problème, un seul algorithmeTout doit avoir un but extrêmement précis, mais c'est un cercle vicieux, puisque plus l'algorithme est tordu, moins on s'autorise à envisager qu'il puisse servir pour beaucoup de situations. A l'inverse, la pratique du data mining réclame qu'on ne se fixe pas d'a priori sur ce que l'on cherche, même si les connaissances a priori comme les classificateurs donnent des résultats très intéressants dans les méthodes supervisées.
De fait, la forme de connaissance la plus importante que puisse acquérir un data miner n'est pas la qualification théorique de tel ou tel algorithme, mais la combinatoire de boîtes algorithmiques disponibles. Cette connaissance est appelée filière de calcul, et pose quelques problèmes de modélisation dans les formats de fichiers.
Enfin, peut-être faut-il admettre qu'il y a eu une pointe de jalousie de la part des français sur l'activité américaine ? Le data mining a pris une ampleur telle :
| Français | Anglais |
| Lettre A | |
| analyse canonique | generalized single value decomposition (GSVD) |
| analyse discriminante | machine learning |
| analyse discriminante à but décisionnel | learner |
| analyse discriminante à but descriptif | wrapper approach |
| analyse factorielle des correspondances | scoring |
| analyse multicritères | multidimensional scaling |
| analyse par composantes principales | principal component analysis |
| arbre de décision | tree learner |
| Lettre C | |
| classes d'une "nuée dynamique" | flat cluster |
| classification ascendante hiérarchique | bottom-up cluster |
| classification descendante hiérarchique | top-down cluster |
| classification non-supervisée | clustering |
| courbe de performance d'un classificateur | ROC curve |
| Lettre E | |
| étalons d'une "nuée dynamique" | centroids |
| Lettre I | |
| individu | example |
| inertie | ? |
| Lettre N | |
| nuage d'individus | exampleset |
| "nuées dynamiques" | K-means |
| Lettre O | |
| ordonnancement de variables | attribute weighting |
| Lettre P | |
| pondération d'individus | weighted example |
| Lettre R | |
| réduction de variables | dimension reduction |
| Lettre S | |
| segmentation | drill-down |
| Lettre V | |
| variable étudiée | label |
| variable explicative | attribute |
| variable synthétique | feature |
| variables en synergie | nested subset |
| mots sans équivalents | |
| ? | bagging |
| ? | bootstrapping |
| ? | Feature Selection |
| ? | learner boosting |
Le cloisonnement des métiers
Une des conséquences directes de l'approche française - en particulier en data mining - est celle de chercher un objectif, une légitimité pour faire, avant même d'essayer un moyen, un outil. Désormais, pour le data miner que vous êtes devenu, il est évident que cette disposition d'esprit est une classification supervisée dans un problème multi-classes...Il sera dès lors très difficile de faire comprendre que le data mining fonctionne d'une certaine manière, et donc que l'on peut imaginer qu'il puisse servir pour plusieurs usages. Vous serez certainement obligé de développer, détailler algorithme par algorithme les usages qui en ont été faits et que l'on pourrait en faire; dans la centrale Yale, il y a près de 200 algorithmes, sans compter toutes les combinatoires possibles...Autant dire que demain vous y êtes encore !
Du point de vue cognitif, cela correspond à une organisation hiérarchique en arbre qui ne tolèrerait pas les graphes de concept. Si vous êtes commercial, vous n'êtes pas financier ni technicien. Le data mining peut rendre service par exemple aux ingénieurs électroniciens[4], mais il y aura un service pour les ingénieurs, et un service pour les data miners, les deux se regardant avec superbe, et la direction n'ayant ni la connaissance, ni l'intention ni l'envie de travailler pour changer les pratiques sociales à ce niveau.
Ce phénomène est extrêmement typique des sociétés latines dont l'histoire a poussé les peuples à percevoir l'état comme un "parent" protecteur, que l'on va aimer ou détester mais dont on ne saurait se passer. A l'inverse, les sociétés anglosaxonnes protestantes ont intériorisé cette autorité, ce qui les pousse à avoir une conception particulière de la responsabilité individuelle, indissociable de la liberté.
De même, pour un protestant, l'humain est prédestiné, mais il ne peut pas le savoir a priori : les protestants ont donc l'obsession d'être créatifs, constructifs de manière à s'assurer qu'ils ont la grâce divine. Le rapport au monde du travail est crucial pour eux, un individu ne se réalise socialement que s'il se réalise professionnellement. A l'inverse, les sociétés latines sont des sociétés paysannes à qui les religions hiérarchisées ont enseigné la pauvreté et l'humilité de Jésus, et leur souci principal sera d'assurer la subsistance du quotidien, d'assurer une dignité qu'ils ne croient pas avoir, assurer la qualité de vie du domaine affectif tout en restant pauvre.
Le résultat est que certains producteurs de littérature, en particulier dans les administrations et les circuits de décision politique, en ont conclu que la prospective à 20 ans (la dernière version du Gosplan) de nos sociétés serait de passer des sociétés hiérarchisées à des sociétés "en rateau", comprenez : l'équilibre géopolitique du monde donne la prééminence au modèle américain, donc le modèle latin dont l'Église catholique se porte caution perd du terrain.
C'est toute une façon de penser qui change, et donc de travailler sur l'organisation des groupes sociaux.
Le sentiment du "Big Brother"
Une des difficultés majeures de mettre en place un système à base d'indicateurs est le sentiment d'être "fliqué". C'est la référence, dont je me servirai par la suite, au film "1984" qui illustre un roman éponyme de George Orwell. L'auteur est un ancien communiste "repenti" après avoir visité l'URSS de Staline et ses villégiatures en Sibérie. Son roman a été écrit en 1948, et a choisi le titre en inversant les deux derniers chiffres de l'année 48.Il décrit dans son roman une société terrifiante où tout, absolument tout est contrôlé et surtout la manière de penser. Il existe pour cela la PenséePol ou police de la pensée; des scientifiques, entre autre des linguistes travaillent à la refonte du langage, des neurologues travaillent à désamorcer la pulsion sexuelle pour l'orienter vers les buts sociaux qu'a planifiés le Parti Unique. Vous êtes écoutés, observés en permanence, et vos peurs les plus intimes sont découvertes et consignées pour être réutilisées lors des séances de rééducation sociale. Au sommet de la pyramide, un seul maître, le Grand Frère moustachu, d'où l'expression Big Brother is watching you, le Grand Frère te regarde.
C'est donc à cette image, cette peur visuelle que renvoie l'expression employée dans le titre. Plus de traçabilité, c'est plus de contrôle et qui sait les mesures rétorsives qui pourraient être prises à l'encontre des employés "rebelles", "paresseux" ou tout simplement surnuméraires sur la charge salariale ? Le système des indicateurs est particulièrement rationnel, mais cette rationalité visuelle est jetée à la figure de tout un chacun, elle se doit donc d'être apprivoisée. Ceux qui ont déjà travaillé avec de tels indicateurs savent que l'on ne peut plus s'en passer, car de facto les mesures et les actions que vous prendrez auront des effets efficaces dès lors qu'elles sont mesurables. Une vérité tellement affutée qu'elle en blesse les consciences.
Alors, qu'est-ce qui fait la différence entre une société "Big Brother" et un pilotage par indicateurs réussi ? La différence réside dans la constante remise en question des décisions prises. Une société totalitaire ne dévie jamais de sa ligne politique, les moyens mis en oeuvre sont de plus en plus intrusifs et coûteux pour rectifier l'écart entre les pratiques et l'idéologie. A l'inverse, un système d'aide à la décision élabore des décisions en fonction de mesures, décisions que seul l'utilisateur pourra prendre. Personne ne peut donc dire ce que sera demain, et la valeur des indicateurs prédictifs est celle de l'expérience acquise, pas d'une façon de penser extérieure. Toute déviance entre ce qui est prévu et réalisé constitue en soi un enseignement de plus en plus précieux, et permettra justement de limiter la casse par apprentissage.
Les acteurs sociaux et la juridiction ont un rôle non-négligeable à jouer dans cette partie puisque tout enregistrement informatique de données personnelles nécessite une déclaration à la CNIL de la structure du moyen de stockage (dictionnaire de métadonnées), ainsi que de sa finalité prévue (description du réglage de l'ETL et des bases OLAP), et fournit un droit d'accès à ces données. Une telle loi protège on ne peut plus efficacement le citoyen contre toute dérive d'un système de traçabilité. Aux États-Unis, cette même problématique s'est retrouvée avec la nécessité de laisser anonyme les personnes inscrites à l'annuaire d'une entreprise. Cela implique une structure particulière des entrepôts, où le repérage des personnes (nécessaire pour avoir une efficacité intelligente et spectaculaire des aides à la décision et à la connaissance) se fait par un numéro. La table de correspondance entre ce numéro et l'identité de la personne est enregistrée dans une base de données séparée, dont l'isolement est sous le couvert de la loi. Cette technique est appelée anonymizing, LA problématique spécifique du data mining.
Ainsi rappelez-vous qu'autant pour les sondages, fussent-ils présidentiels ou non, les inscriptions par compte et mot de passe aux services Internet, que les systèmes d'entreprise, la clause "d'anonymizing" doit toujours être respectée. En conséquence, les données vous concernant pourront être diffusées à des tierces parties à l'expresse condition que votre anonymat soit conservé. Après tout, c'est bien suffisant pour extraire une règle d'association par exemple, puisque les individus n'y sont pas mentionnés.
A l'inverse, il y aurait beaucoup à dire de l'accord de crédit à telle ou telle personne selon son comportement financier et sa rentabilité estimée. N'est-ce pas de la discrimination, l'analyse discriminante ?
De même, la problématique du croisement des fichiers administratifs est typiquement un problème de data mining, puisque vous consoliderez des dictionnaires de métadonnées en augmentant le nombre d'attributs par individus (lien entre fiscalité, casier judiciaire, consommation, endettement, déplacements géographiques), ce qui permettra de tracer des profils comportementaux extrêmement précis sur les individus (et je ne vous parle pas des classificateurs qui anticiperaient vos comportements, vos orientations de carrière, vos choix politiques, etc...), et là il s'agit bien de rentrer dans l'identité de chacun. De ce dont j'ai pu discuter avec des professionnels, ce genre de mesures de sécurité intérieure vise à répondre à des problèmes d'ordre géopolitique que ces mêmes décideurs ont un jour ou l'autre eux-mêmes créés.
En outre, les structures administratives ne sont pas les structures d'entreprise : Depuis Montesquieu, on sait désormais que toute démocratie repose sur la séparation de la monarchie présidentielle...pardon, du pouvoir exécutif[5], du pouvoir législatif des "chambres" (sénat, assemblée nationale en France, etc...) et du pouvoir judiciaire (hors tribunaux administratifs). Qui donc devrait bénéficier des résultats consolidés de ces fichiers administratifs ? Là est le vrai travail.
José Bové avait réussi à casser un MacDonald installé par les légions romaines, c'est normal, il avait pris une bonne rasade de potion magique qui lui avait secoué les moustaches !! Plus sérieusement, rappelez-vous que le problème portait entre autres sur les viandes bovines supposées contaminées. Ce phénomène fut tellement décisif sur l'image de marque de la marque américaine et donc sur son chiffre d'affaires qu'une traçabilité du tonnerre fut mise en place. Les employés de MacDonald ne se sont-ils pas sentis fliqués de tout marquer, de tout tracer ? Pourtant cette traçabilité fut réclamée à corps et à cris !
Le problème du Big Brother est donc de jouer franc-jeu et d'être pragmatique sur les choix techniques sans a priori ni croyances ni pseudo-expertises. Le système a tout intérêt à être transparent, car si j'ose dire dans la nudité tout se voit : Le premier comportement social qui s'éloignerait des valeurs du groupe, le premier discours pervers serait vite démasqué et ce autant pour les employés que la direction. Dans cette affaire, tout n'est que rationalité aveugle.
Une approche empirique difficile à vendre
Une conséquence naturelle de tout ce qui précède est qu'il est difficile de faire envisager aux décideurs les bénéfices dont ils pourraient retirer d'une démarche de KDD. Par ailleurs, la phase la plus critique est celle de la spécification : comment faire accepter à un maître d'ouvrage de spécifier le projet de KDD d'une certaine manière qui n'est pas celle dont il a l'habitude ? Il aura l'impression de perdre la main sur son projet.La méthode traditionnelle de spécification d'un projet commence d'abord par assigner un objectif et le qualifier en termes de pertinence :
- Pourquoi veut-on faire cela ? Quelle est la vraie motivation ?
- Y a-t-il un objet différent de celui que l'on perçoit qui rendrait le même service attendu ?
- Ce projet a-t-il été déjà fait quelque part par d'autres ?
- Après analyse, combien coûterait un tel projet (argent, temps, modification des structures) et en a-t-on les moyens ?
C'est souvent dans ces phases de qualification d'objectif qu'intervient le choix des bonnes variables. Qu'est-ce qui est important, qu'est-ce qui conditionne le projet ? Ben justement, une démarche de data mining déclenchée avant la phase de spécification du projet aurait permis d'effectuer ce travail, qui techniquement correspond à une phase d'ACP ou de Feature Selection, et de manière beaucoup plus rapide, complète, rationnelle et fiable qu'une discussion de salon entre connoisseurs.
Donc, à l'inverse des traditions et usages de la gestion de projet, moins on spécifie d'objectifs, plus tôt on applique la démarche KDD, mieux on se porte. Autant dire que c'est une gageure dans un groupe qui n'y serait pas intellectuellement préparé !
Si la spécification d'objectifs est réduite à portion congrue, il se dégage en revanche le besoin impératif de faire l'inventaire des pratiques, des systèmes en place : ça peut servir pour le scripting de prétraitement et le choix des dictionnaires d'attributs à consolider. A la rigueur, on peut spécifier pour le début d'étude un domaine métier, un périmètre de travail qui de toute façon tombera en cours d'étude si le data mining est efficace et convaincant. La référence en ce domaine est Ralph Kimball, en l'occurrence son "guide de la conduite de projet d'un datawarehouse[6]".
Le choix des bonnes variables
Les entreprises qui ont tenté la démarche KDD sont désormais fières d'annoncer leurs résultats, mais aussi parfois de faire la promotion de la machinerie qui les soutient. "Je dispose d'un système expert multi-agents", "nous c'est un réseau de logique floue qui nous permet d'anticiper sur la concurrence", etc...Tous ces vocables impressionnants ont un point commun : Ce sont des classificateurs essentiellement. La lisibilité du système n'est assurée que s'il est capable de générer des décisions visualisables; cela explique que les entreprises soient demandeuses de classificateurs et de règles d'association.
Pourtant, l'expérience montre clairement que c'est le choix des bonnes variables qui déterminera le succès de l'opération. Par choix, j'entends les phases de réduction de dimension et Feature Selection. En effet, pourquoi a-t-on besoin de classificateurs aussi complexes et spectaculaires que des réseaux de neurones, des réseaux bayésiens ou des forêts aléatoires (combinaison multiple d'arbres de décision) ? En fait, pour deux raisons :
- Ces modèles sont visualisables, ce qui permet de concrétiser et conceptualiser une connaissance abstraite que détient l'entreprise
- Ces modèles répondent à des connaissances non-linéaires, ils représentent des associations entre données et phénomènes qui ne suivent pas une simple loi de proportionnalité ou de superposition des grandeurs. D'où leur polyvalence qui conduit à les utiliser de manière systématique
Or c'est justement la phase de choix des variables qui permet d'introduire cette connaissance "métier" dans le processus d'analyse, notamment :
- La sélection des variables peut être très sophistiquée, en particulier un Nested Subset Selection grâce à un wrapper peut aller jusqu'à décortiquer et expliciter le fonctionnement interne d'un réseau de neurones, généralement très opaque
- La réduction de dimensions permet de créer des axes principaux porteurs d'une thématique expliquable et jusqu'ici diffuse dans les pratiques d'entreprise
- L'aggrégation de variables avant sélection permet d'introduire des attributs non-linéaires, typiquement des logarithmes et des polynômes de variables explicatives, ce qui aura pour effet d'introduire l'algorithmie spécifique d'un métier (cas des sciences de l'ingénieur) et de simplifier considérablement le choix du classificateur. Idéalement, un classificateur devrait être un simple seuil sur un axe de valeurs, séparant le problème en quelques classes; ce serait la garantie que le prétraitement est de qualité.
C'est objectivement un tort. Toute la réussite du projet de KDD dépend de cette phase de prétraitement. Dans ce genre de classificateurs complexes, c'est l'algorithme interne qui fait tout le boulot de prétraitement sur les variables qui aurait dû être fait en amont par le data miner. C'est le cas des algorithmes type "Support Vector Machine", "Fonctions à noyaux", "Réseaux de Neurones", "Réseaux Bayésiens".
Etude de cas concrets
Récemment j'ai été contacté par un étudiant de l'ENST Bretagne. Celui-ci était bloqué depuis trois jours sur un problème d'étude et de comparaison des performances de différents algorithmes de compression des données. Il a pris l'initiative de me contacter pour me demander de l'aide sur la manipulation de l'outil logiciel RapidMiner. J'ai donc accepté de bricoler un peu sur le logiciel, et reprenant les éléments qu'il me transmettait, je suis parvenu à créer un flux de calcul dont j'attends le verdict de son côté.Suite à celà et au cas où le flux de calcul serait satisfaisant, il me propose de citer mon pseudonyme "Hiramash" ainsi que l'adresse du site dans la partie "remerciements/acknowledgments" de son article. Il m'enverrait également une copie. C'est là que j'ai eu l'idée, sous le couvert du bénévolat et dans la limite de mes connaissances d'autodidacte en data mining, de proposer à qui le veut bien de petits coups de main en analyse de données et de publier les cas étudiés dans cette page sous certaines restrictions qui me seraient spécifiées.
En effet, si vous parcourez le Web vous trouverez très peu d'exemples d'applications pratiques de ces techniques, ce qui est probablement en définitive l'obstacle majeur à leur pratique : l'Ignorance.
L'Étude "Télécom Bretagne"
Fichiers PDF téléchargeables sous archives zippées:Autres études
N'hésitez pas à me contacter, j'essaierai de vous aider à titre bénévole...Notes :
[1] En anglais, Knowledge Discovery in Databases ou KDD.
[2] L'exemple le plus célèbre est le banquier qui vous accorde ou non un prêt : il utilise un classificateur "oui/non" sur votre profil de comportement extrait de vos relevés bancaires. Le terme consacré est "scoring", ce qui englobe aussi l'analyse factorielle des correspondances
[3] C'est le principe de l'hypothèse Sapir-Whorff : contrôlez la langue, et vous contrôlez la pensée d'un peuple. D'où le pouvoir des religions...
[4] La génération qui a connu le traitement numérique du signal doit savoir que pratiquement toute la panoplie d'algorithmes de traitement correspond à un preprocessing des données, soit par réduction de dimensions (Fourier et consorts), soit par sélection (filtrage temporel/fréquentiel)
[5] Plaisanterie mise à part, le caractère presque autocratique du président de la Vème République est parfaitement attesté par les juristes, expliquant qu'il avait été sciemment voulu par le Général de Gaulle. Celui-ci avait un souvenir très désagréable de l'instabilité maladive de la quatrième république, et hésitait à restaurer la royauté en France...
[6] Le datawarehouse est le nom anglais pour entrepôt de données. On le trouvera sous la forme abrégée DWH.
[7] Étant entendu qu'un arbre, entre autres définitions issues de la théorie des graphes, est une liste dont chaque élément est lui-même une liste, comme en langage LISP
Retour à l'accueil
Remonter d'un niveau